We learned how to launch an EC2 instance from an Amazon AMI with a batched gekko/gekkoga app/conf deployment. Now we will learn how to use it on a more powerful, larger CPU-optimized instance at a good price (Amazon EC2 Spot feature), so that we can -literally- quickly bruteforce all possible parameters and inputs of a given trading strategy, using Gekkoga’s genetic algorithm.
The main documentations we will use:
- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-requests.html
- https://aws.amazon.com/ec2/spot/pricing/
Step 1: associate a new AWSServiceRoleForEC2Spot IAM role
As explained in Amazon’s documentation, we first need to create a new role AWSServiceRoleForEC2Spot in our AWS web console. This is just a few clicks, please read their doc:
By using the console
- Open the IAM console at https://console.aws.amazon.com/iam/.
- In the navigation pane, choose Roles.
- Choose Create role.
- On the Select type of trusted entity page, choose EC2, EC2 – Spot Instances, Next: Permissions.
- On the next page, choose Next:Review.
- On the Review page, choose Create role.
By using your ec2 CLI
aws iam create-service-linked-role --aws-service-name spot.amazonaws.comStep 2: handling Amazon’s VMs automatic shutdown for Spot instances
Next we need to take care of Amazon’s automatic shutdown of Spot instances, as it depends on market price, or on the fixed duration of usage you specified in your instantiation request. When Amazon decides to shutdown an instance, it will send a technical notification to the VM, that we can watch and query using an URL endpoint. Yes it means that we will need to embed a new script in our EC2 Reference AMI, to handle such a shutdown event, and make it execute appropriate actions before the VM is stopped.
Note: Amazon announces a two-minute delay between the termination notification and the actual shutdown. This is short.
The way I chose to do it (but there are others) is to launch a ‘backgrounded’, recurrent, script at VM boot through our already modified rc.local, and this script will poll every 5 seconds the appropriate metadata using a curl call. If the right metadata is provided by Amazon, then we execute a customized shutdown script. This shutdown script therefore needs to be embedded in the customized package our VM will automatically download from our reference server at boot time.
Now, we boot a new VM based on our last AMI. We insert those 3 new lines just before the last “exit 0” instruction in the VM’s /etc/rc.local file:
echo "Launching background script to handle termination events ..."
/etc/rc.termination.handling &
echo "Done."Then we create a /etc/rc.termination.handling script, based on indications from amazon’s documentation. Beware to modify line 17, 19, 20 and 22 so that your Gekkoga results and various logs will be synced in a timestamped directory:
#!/bin/bash
while true; do
if curl -s http://169.254.169.254/latest/meta-data/spot/instance-action | grep -q -E 'stop|terminate|hibernate'
#for testing shutdown script
# if curl -s http://169.254.169.254/latest/meta-data/spot/instance-action | grep -q -E '404'
then
d=$(date +%Y%m%d_%H%M%S)
#logging in a timestamped shutdown log file and in console
exec >> >(tee /home/ec2-user/AWS/logs/${d}_shutdown.log|logger -t user-data -s 2>/dev/console) 2>&1
echo "Received a termination notification on $d"
echo "Launching termination commands"
# stopping pm2 process (ui & Gekkoga. Nota we should better use their names instead of theorical id)
su ec2-user -c "pm2 stop 1 2"
# archival of the results in a timestamped dir
su ec2-user -c "cd /home/ec2-user && cp -R gekko/gekkoga/results AWS/results/${d}_results"
# create the same timestamped dir on our reference server @home
ssh <YOUR_C&C_SERVER> "mkdir /home/gekko/AWS/results/${d}_results"
# upload the results on our reference server @home in two different places
scp -r /home/ec2-user/AWS/results/${d}_results/* <YOUR_C&C_SERVER>:/home/gekko/AWS/results/${d}_results
scp -r /home/ec2-user/AWS/results/${d}_results/* <YOUR_C&C_SERVER>:/home/gekko/gekko/gekkoga/results
# archive the shutdown logs on our reference server
scp -r /home/ec2-user/AWS/logs/${d}_shutdown.log <YOUR_C&C_SERVER>:/home/gekko/AWS/logs
echo "Done."
echo "===== End of Gekko Termination script ====="
break
fi
sleep 5
doneWe make it executable:
sudo chmod u+x /etc/rc.termination.handlingWe will now test if this is working. The only thing we won’t be able to test right now is the real URL endpoint with terminations informations. First, we reboot our EC2 reference VM and we verify that our rc.termination.handling script is running in the background:

Now we will test its execution, but we need to slightly change its trigger as our VM is not yet a Spot instance and the URL we check won’t embed any termination information, therefore it will return a 404 error. I also disabled the loop so that it will just execute once.
#!/bin/bash
# while true; do
# if curl -s http://169.254.169.254/latest/meta-data/spot/instance-action | grep -q -E 'stop|terminate|hibernate'
# for testing shutdown script
if curl -s http://169.254.169.254/latest/meta-data/spot/instance-action | grep -q -E '404'
then
d=$(date +%Y%m%d_%H%M%S)
#logging in a timestamped shutdown log file and in console
exec >> >(tee /home/ec2-user/AWS/logs/${d}_shutdown.log|logger -t user-data -s 2>/dev/console) 2>&1
echo "Received a termination notification on $d"
echo "Launching termination commands"
# stopping pm2 process (ui & Gekkoga)
su ec2-user -c "pm2 stop 1 2"
# archival of the results in a timestamped dir
su ec2-user -c "cd /home/ec2-user && cp -R gekko/gekkoga/results AWS/results/${d}_results"
# create the same timestamped dir on our reference server @home
ssh <YOUR_C&C_SERVER> "mkdir /home/gekko/AWS/results/${d}_results"
# upload the results on our reference server @home in two different places
scp -r /home/ec2-user/AWS/results/${d}_results/* <YOUR_C&C_SERVER>:/home/gekko/AWS/results/${d}_results
scp -r /home/ec2-user/AWS/results/${d}_results/* <YOUR_C&C_SERVER>:/home/gekko/gekko/gekkoga/results
# archive the shutdown logs on our reference server
scp -r /home/ec2-user/AWS/logs/${d}_shutdown.log <YOUR_C&C_SERVER>:/home/gekko/AWS/logs
echo "Done."
echo "===== End of Gekko Termination script ====="
break
fi
sleep 5
# doneWe manually execute it, and we check the output log in $HOME/AWS/logs:

Now we check on our Reference server @home if the results were uploaded by the EC2 VM.

That’s perfect !
Don’t forget to cancel the modifications you made previously in rc.termination.handling to test everything: the loop needs to be enabled, and the curl checking any 404 needs to be disabled (exactly as in the first script example above).
And you need to create now a new AMI reference based on this Virtual Machine ! From now on, all requests you will make to create a new instance shall use this new AMI reference ID.
Step 3: checking Spot Instances price
First we need to know what kind of VM we want, and then we need to check the Spot price trends to decide for a price.
For my first test, I will choose a c5.2xlarge, it embeds 8 vCPU and 16Gb of memory. It should be enough to launch Gekkoga with 7 concurrent threads.
Then we check the price trends and we see that the basic market price is -at the moment- around $0.14, this will be our base price in our request as we just want to test for now.
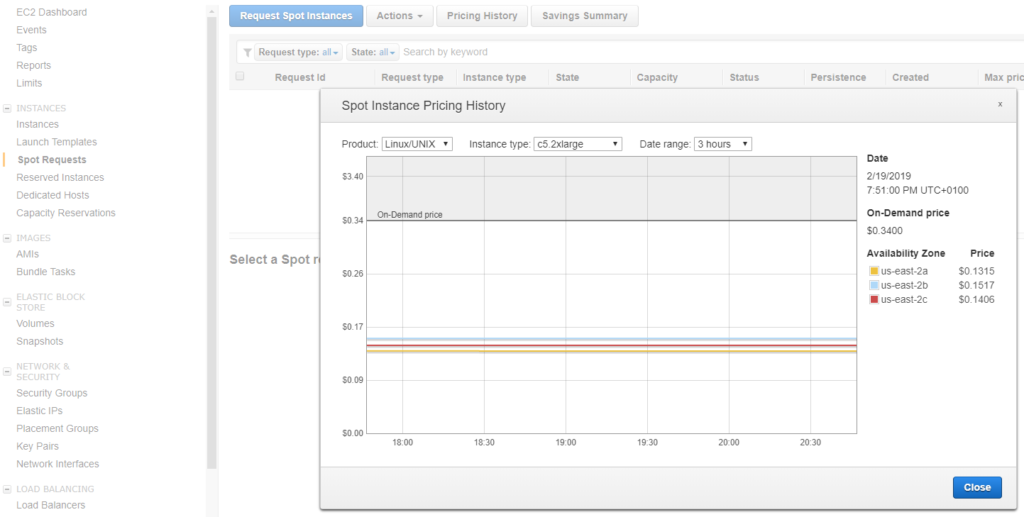
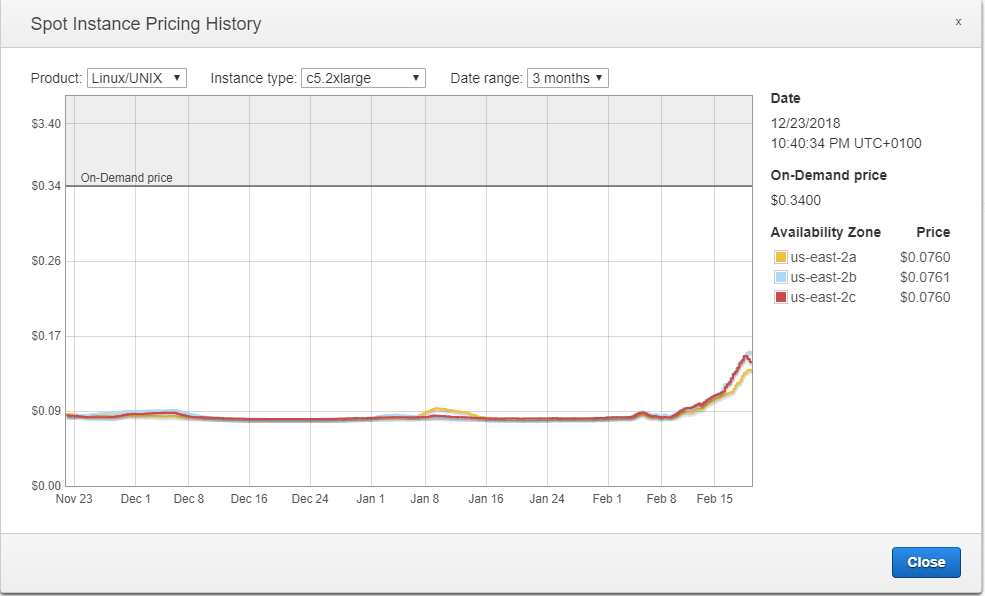
It is also interesting to look at the whole price trend over a few months, and we can see it actually increased a lot. Maybe we could obtain more powerful instances for the same price.
Let’s check the price for the c5.4xlarge VM :
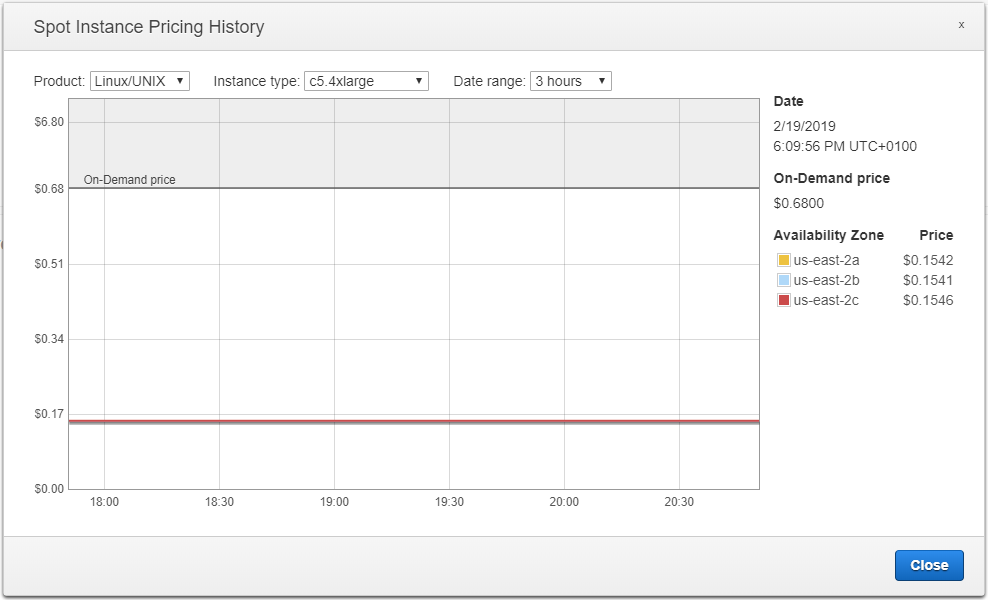
Conclusion: at the moment I write this part of the article, for $0.01 more, we can have a c5.4xlarge with 16 vCPU and 32Gb of RAM instead of a c5.2xlarge with 8 vCPU and 16Gb of RAM. Let’s go for it.
Step 4: requesting a “one-time” Spot Instance from AWS CLI
On our Reference server @home, we will next use this AWS CLI command. I’ve embedded it in a shell script called start_aws.sh, located in $HOME/AWS on my home C&C server. For more details on the json file to provide with the request see Amazon’s documentation. I describe the file I use here a few lines after.
#!/bin/bash
aws ec2 request-spot-instances --block-duration-minutes 60 --spot-price "0.34" --type "one-time" --launch-specification file://spot_specification.json --dry-runNote:
- The –dry-run parameter: it asks the CLI to simulate the request and display any error instead of really trying to launch a Spot instance.
- This time, for my first test, I used a “one-time” VM (–type “one-time”) with a fixed duration execution time (–block-duration-minutes 60), to make sure to know how long it will run, and therefore the price is higher as the one we saw above !
- Once our test is successfull, we will use “spot” VMs with prices we can “request” depending on the market, but also with a run time we can’t anticipate (it may be stopped anytime by Amazon if our calling price becomes lower than the market price. Otherwise you will have to stop it yourself).
Then we create a $HOME/AWS/spot_specification.json file and we use appropriate data, especially our latest AMI reference, virtual machine type, the requested price, the regional zone to run it:
{
"ImageId": "ami-0f32add64a9f98476",
"KeyName": "gekko",
"SecurityGroupIds": [ "sg-0acff95acbe908ed3" ],
"InstanceType": "c5.4xlarge",
"Placement": {
"AvailabilityZone": "us-east-2"
},
"IamInstanceProfile": {
"Arn": "arn:aws:iam::022191923083:role/Administrator"
}
}We try the above aws cli command line to simulate a request …

Seems all good. let’s remove the –dry-run and launch it.
#!/bin/bash
aws ec2 request-spot-instances --block-duration-minutes 60 --spot-price "0.34" --type "one-time" --launch-specification file://spot_specification.json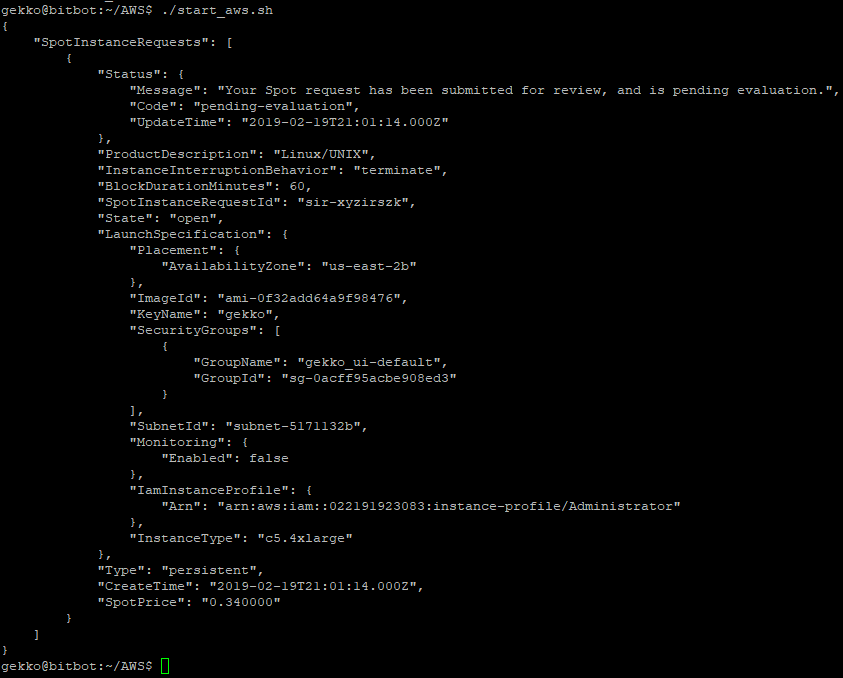
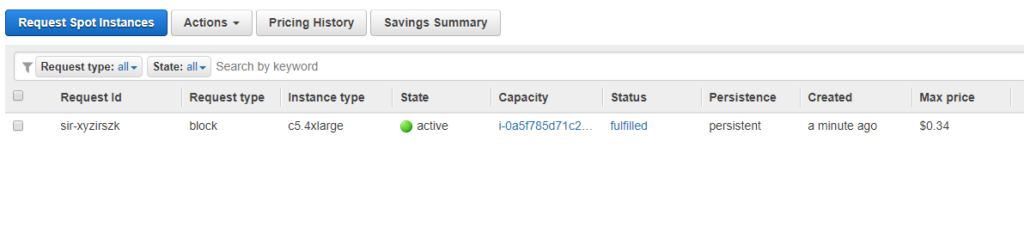
On the EC2 Web console we can see our request, and it is already active, it means the VM was launched !
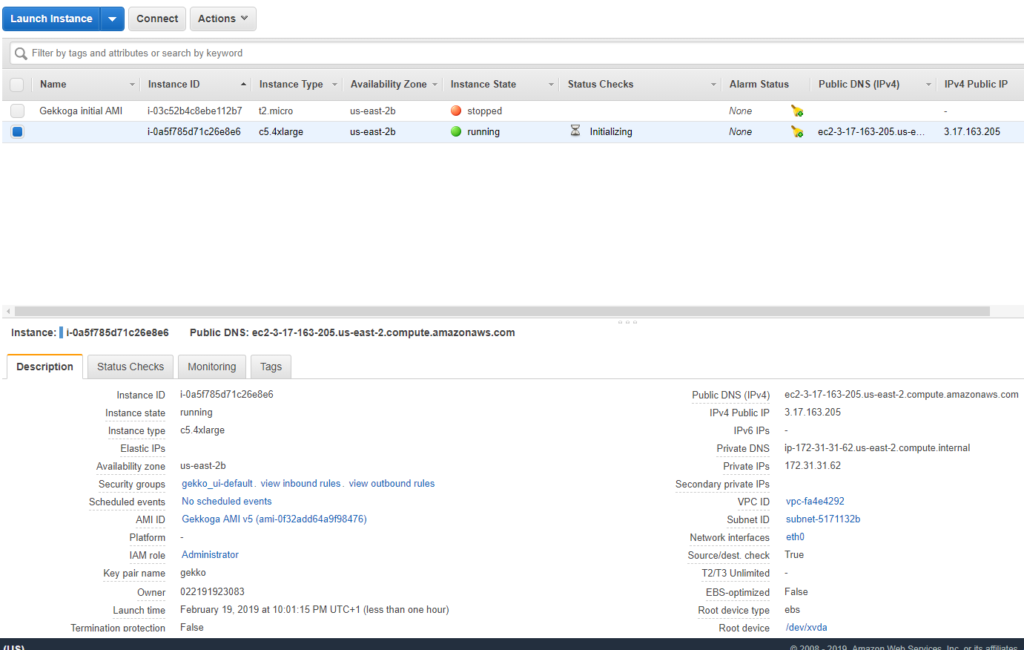
Now in the main dashboard we can see it running, and we get its IP (we could do it via AWS CLI also):
Let’s SSH to it and check the running process:
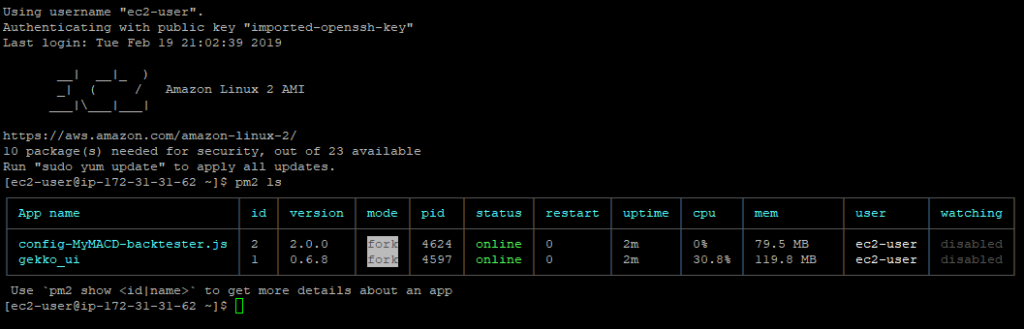
We can see that both Gekko and GekkoGA are running … This is a very good point.
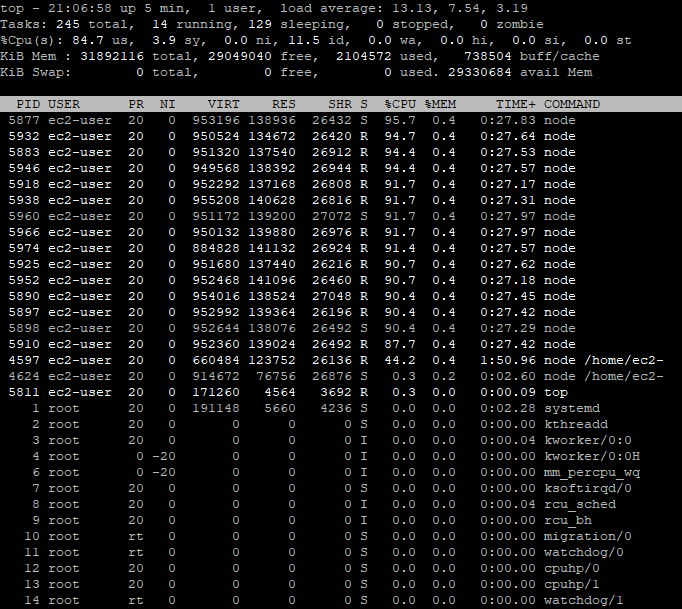
It seems to be running as we can notice 84.7% of the CPUs are used, which is quite high, but normal with GekkoGA. And actually you can’t see this but this is running well, as I keep receiving emails with new “top result” found from Gekkoga as I activated the emails notifications. This is a good way to also make sure you will backup the latest optimum parameters found (once again: this is a backtest and in no way it means those parameters are good for the live market).
Step 5: first performance evaluation
Let’s dig inside the logs:
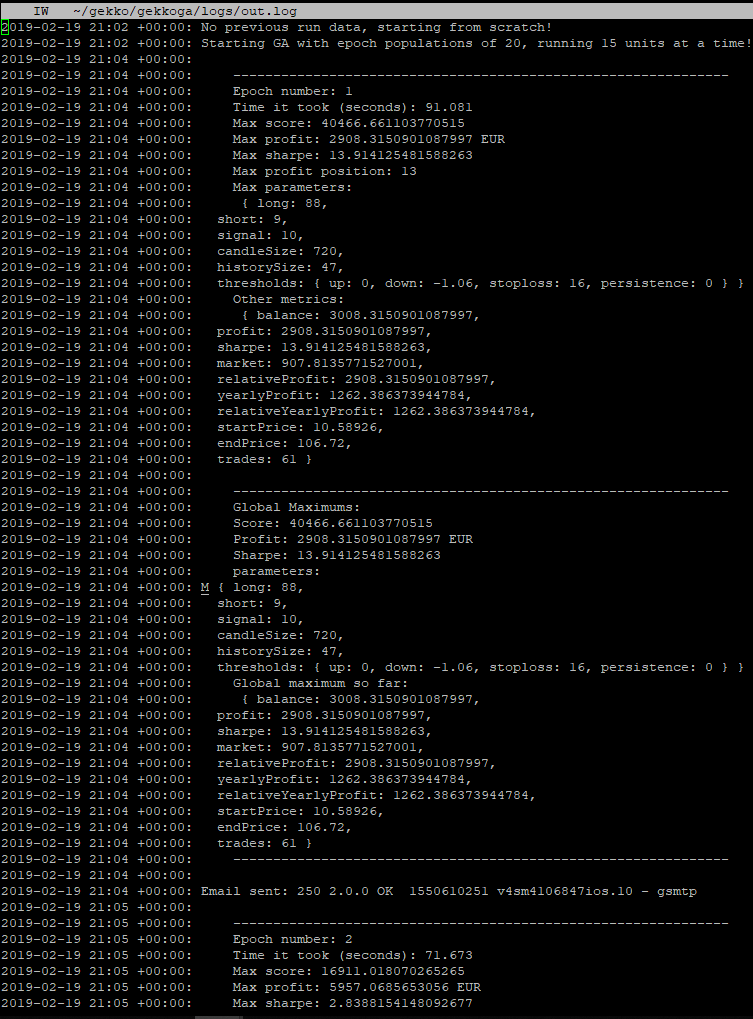
It’s running well ! Now I’ll just wait one hour to check if our termination detection process is running good and if it backups the result to our Reference server @home.
While we are waiting though … Let’s have a look in the logs, on the computation time:
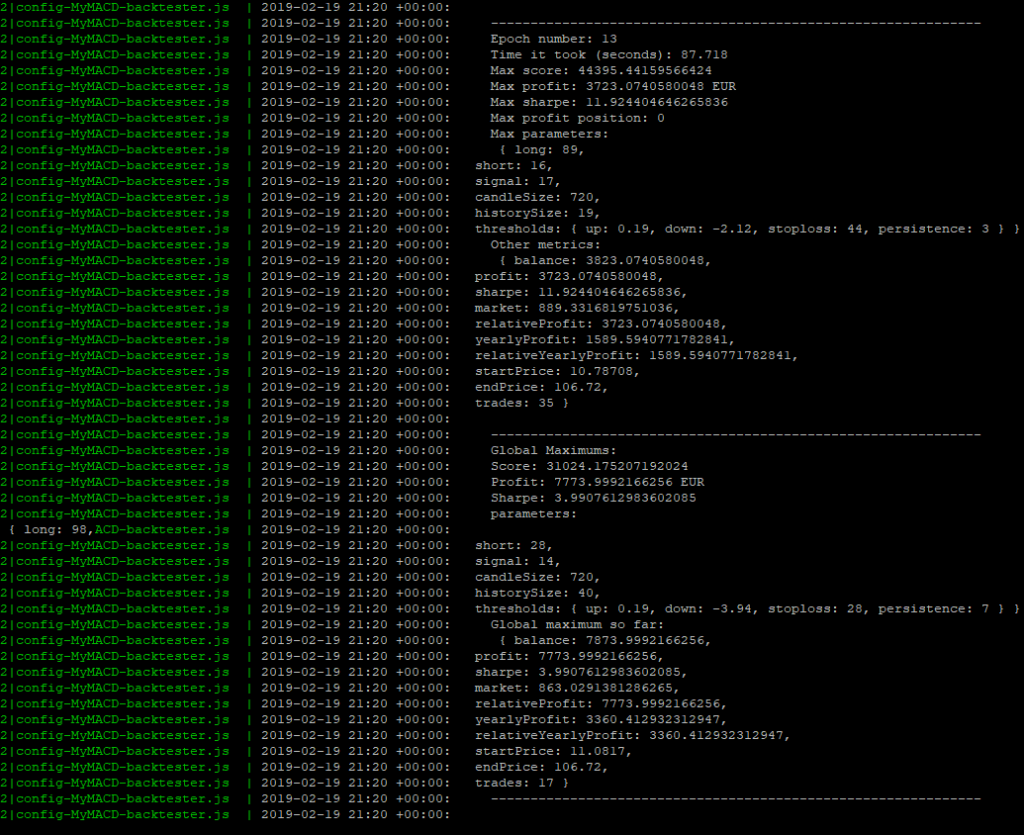
Epoch #13: 87.718s (~1.30 minute). Well, it depends on the parameters specified inside our test strategy and on the strategy itself, but last time we had a look at it, epoc #1 took 1280.646s (~21 minutes) to complete on our home virtual machine, for the same strategy we customized as an exercise. This is a factor 14,5 gain … It can be easily explained as:
- We have 16 CPU on the VM and we tweaked our GekkoGA’s starting script to use N-1 = 15 CPU
- We didn’t change Gekkoga’s populationAmt parameter, which is set on 20 by default (not far from the number of CPU).
- Conclusion: GekkoGA is almost able to launch one backtest per CPU to complet a whole epoch.
One hour later, I managed to come back 2mn before the estimated termination time (requested when we launched the Virtual Machine, in our json file) and I could manually check with curl that the termination meta-data were sent by Amazon to the VM.
Our termination script performed well and uploaded the data on my Reference server @home, both in the ~/AWS/<timestamp>_results and in gekkoga/results dir so that it will be reused at next launched by Gekkoga.
Step 6: using a Spot instance with a “called” market price
In previous steps we learned how to request a “one-time” spot instance with a fixed duration time, which means we ensured it would run for a specified duration, but at a higher and fixed price. Because we managed to backup the data before its termination, and also because Gekkoga knows how to reuse previous data it finds, we will now use lower priced Spot instances, but with no guarantee it will run long.
Let’s modify our AWS cli request .. And let’s be a little bit crazy, we will test a c5.18xlarge (72 CPU, 144Gb of RAM) at a market price of $0.73 per hour. Notice the differences ? No more –block-duration-minutes 60 or –type “one-time” parameters.
#!/bin/bash
aws ec2 request-spot-instances --spot-price "0.73" --launch-specification file://spot_specification.json{
"ImageId": "ami-0f32add64a9f98476",
"KeyName": "gekko",
"SecurityGroupIds": [ "sg-0acff95acbe908ed3" ],
"InstanceType": "c5.18xlarge",
"Placement": {
"AvailabilityZone": "us-east-2b"
},
"IamInstanceProfile": {
"Arn": "arn:aws:iam::022191923083:instance-profile/Administrator"
}
}Amazon started it quite immediately. Let’s SSH it and check the number of process launched.
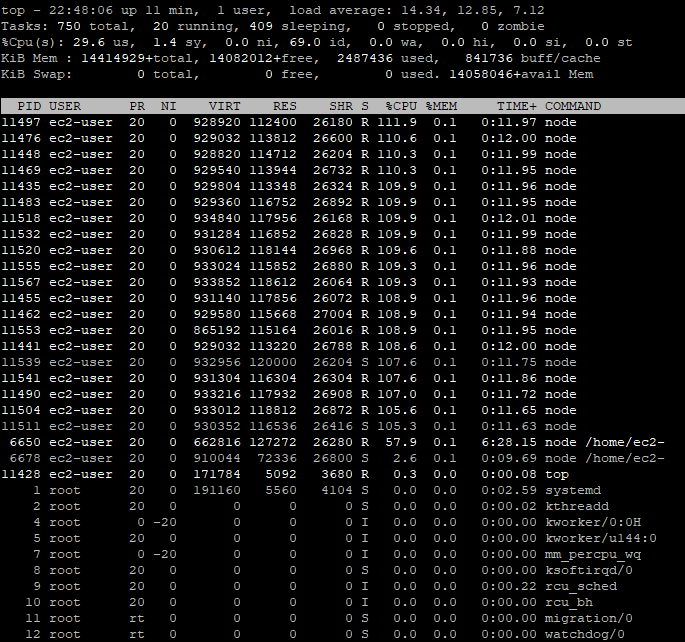
So … This is quite interesting because parallelqueries in gekkoga/config/config-MyMACD-backtester.js is well set to 71, BUT it seems the maximum node processes launched will cap to 23. It means there is no need to launch a 72 CPU VM, whith actual settings for the strategy & GekkoGA. A 16 or 32 CPU may be enough for now.
The explanation is that the populationAmt parameter in GekkoGA’s config file is limiting the number of threads launched. Setting it up to 70, still with a parallelqueries to 71, will make the number of threads to increase, and stabilize around 70 but with some periods down to 15 threads. Would be interesting to graph it & study it, but it will be in a next article. Maybe there is also a bottleneck on Gekko’s UI/API which has to handle a lot of connections from all Gekkoga’s backtesting threads.
// Population size, better reduce this for larger data
populationAmt: 20,
// How many completely new units will be added to the population (populationAmt * variation must be a whole number!!)
variation: 0.5,
// How many components maximum to mutate at once
mutateElements: 7,Now, I’ll need to start to read a little bit more litterature on this subject to find a good tweak … Anyway right now i’m using 140 for populationAmt and I still experience some dips down to 15 concurrent threads for nodejs.
Step 7 : Evolution of “estimated profits” on past market
After 12 hours without any interruption (so, total cost = $0.73*12 = $8,76), those are all the mails I received for this first test with our previously customized MyMACD Strategy.

As you can see, with this strategy, the profit is much better with long candles and long signals. Again, this needs to be challenged on smaller datasets, especially “stalling” markets, or bullish markets as nowadays. This setup and automation of tests will not guarantee you, in any way, to earn money. But it is definitely a new and good tool to massively test new strategies.
A note about memory usage
I tried several kind of machines, right now I’m using a c4.8xlarge which has still good CPUs but lower RAM than the c5 family. And I started to test another customized strategy. I encountered a few crashes.
- I initially thought it was because of the CPU usage capping to 100 as I increased the number of parallelqueries and populationAmt. I had to cancel my spots requests to kill the VMs.
- Using the EC2 Console, I checked the console logs, and I could clearly see some OOM (Out of Memory) errors just before the crash.
What I did:
- I went into my strategy code and tried to simplify everything I could, by:
- Using ‘let’ declarations instead of ‘var’ (to reduce the scope of some variables),
- Removing one or two variables I could handle differently,
- Commenting out every condition displaying logs, as I like to have log in my console when Gekko is trading live. But for backtesting, avoid it: no log at all, and eliminate every condition you can.
- I also reduced the max_old_space_size parameter to 4096 in gekko/gekkoga/start_gekkoga.sh.
- It has a direct impact on Node’s Garbage Collector.
- It will make the GC collect the dust (non used data) twice often than with the 8096 I previously configured.
Since those two changes, i’m running a new intensive GekkoGA session on a c4.8xlarge since a few hours, using 34 parallelqueries vs 36 vCPUs. The CPUs are permanently 85% busy which seems good to me.
Step 8: improvements
Mail notification upon VM boot or termination
I simply wanted to be notified when a request for a Spot instance is fulfilled, by an email. I’m mostly using gmail accounts, so the simplest way I found is to use ssmtp and it is described here:
sudo yum install ssmtpThen edit /etc/ssmtp/ssmtp.conf (use sudo) and use those parameters (I removed all comments from original file and added some to explain what it does). You need to adapt it for your own usage. Please note that Google/gmail won’t allow -soon- the use of specifics applications passwords …
# source address to be used by default in From: field
root=xxxxxxxxxxxxxxxxxx@gmail.com
# gmail server/port
mailhub=smtp.gmail.com:465
# Allows users to set their own From: address (needed to use our root address above)
FromLineOverride=YES
# Standard collection of roots CAs
TLS_CA_File=/etc/pki/tls/certs/ca-bundle.crt
# Login for your source address at gmail
AuthUser=xxxxxxxxxxxxx@gmail.com
# password for your source address at gmail (Use applications password !! Not your main one)
AuthPass=xxxxxxxxxxxxx
# Use a secure SSL/TLS connexion
UseTLS=YESTo test it :
printf "Subject: Test\n\nTesting...1...2...3" | ssmtp yourDestEmail@gmail.comYou should receive the email a few seconds later. Now let’s edit /etc/rc.local to send us an email when the VM will boot, with a few information in it. I just append the code below to the end of my rc.local file (before exit 0).
echo "Sending a notification email to announce our startup ..."
TYPE=$(curl http://169.254.169.254/latest/meta-data/instance-type)
IP=$(curl http://169.254.169.254/latest/meta-data/public-ipv4)
HOSTNAME=$(curl http://169.254.169.254/latest/meta-data/public-hostname)
STRAT=$(cat /home/ec2-user/gekko/gekkoga/start_gekkoga.sh | grep TOLAUNCH= | cut -d "=" -f 2 | cut -d '"' -f 2)
NBCPU=$(getconf _NPROCESSORS_ONLN)
QUERIES=$(cat /home/ec2-user/gekko/gekkoga/config/${STRAT} | grep parallelqueries: | cut -d ":" -f 2 | cut -d "," -f 1 | cut -d " " -f 2)
printf "Subject: EC2 Instance started (${TYPE})!\n\nIP: ${IP}\nHOSTNAME: ${HOSTNAME}\nSTRAT: ${STRAT}\nUsing ${QUERIES} parallelqueries vs ${NBCPU} vCPUs\nType: ${TYPE}\n" | ssmtp yourDestEmail@gmail.com
echo "Done."
echo "===== End of Gekko Packaging Retrieval ====="What this script does:
- Displays in the logs a message indicating that a notification email is being sent.
- Retrieves various details specific to the EC2 instance:
- TYPE: instance type (e.g., t2.micro)
- IP: public IP address
- HOSTNAME: public hostname
- STRAT: name of the launched strategy (extracted from
start_gekkoga.sh) - NBCPU: number of available CPU cores on the VM
- QUERIES: number of parallel queries configured for the strategy in Gekkoga’s configuration file
- Composes an email using this information in the subject/body, and sends it to the desired email address using ssmtp.
- Displays a confirmation message
To adapt:
- Replace
yourDestEmail@gmail.comwith the actual destination email address. - Make sure the paths and variables match your actual configuration.
And, in case of a termination initiated by Amazon, I’ll do the same thing in /etc/rc.termination.handling (here again I just append the code below to the end of the script, before the break/fi/sleep 5/#done lines.
echo "Sending a notification email to announce our termination ..."
TYPE=$(curl http://169.254.169.254/latest/meta-data/instance-type)
IP=$(curl http://169.254.169.254/latest/meta-data/public-ipv4)
HOSTNAME=$(curl http://169.254.169.254/latest/meta-data/public-hostname)
STRAT=$(cat /home/ec2-user/gekko/gekkoga/start_gekkoga.sh | grep TOLAUNCH= | cut -d "=" -f 2 | cut -d '"' -f 2)
NBCPU=$(getconf _NPROCESSORS_ONLN)
QUERIES=$(cat /home/ec2-user/gekko/gekkoga/config/${STRAT} | grep parallelqueries: | cut -d ":" -f 2 | cut -d "," -f 1 | cut -d " " -f 2)
printf "Subject: EC2 Instance will STOP (${TYPE})!\n\nIP: ${IP}\nHOSTNAME: ${HOSTNAME}\nSTRAT: ${STRAT}\nUsing ${QUERIES} parallelqueries vs ${NBCPU} vCPUs\nType: ${TYPE}\n" | ssmtp yourDestEmail@gmail.com
echo "Done."
echo "===== End of Gekko Termination script ====="
break
fi
sleep 5
#done
Here again, to adapt, replace yourDestEmail@gmail.com with the actual notification email address and check paths/variables.
Here is an example of what you will receive if you use above examples. Note that I had a typo in my script, the type of machine at the end of the email is not well formatted below, but I fixed it in the code above when I noticed it:
Live check for new results & automatic rsync with C&C home server
I added a file monitoring utility to “live” detect any change in the Gekkoga’s result directory, to upload it immediately on my Reference Server @home. I had to do this because I noticed that when you ask Amazon to terminate a Spot request whith a running VM associated to it, it indeed almost immediately kills the VM, without announced termination. So, the results where not always synced on my Home C&C server.
Anyway, thanks to emails notification, I had all the details of all the strategy configurations “elected” by the genetic algorithm in my mail box.
Advanced start_aws.sh script for the C&C home server
I developed an AWS machine launch script that is much more advanced than the one used above. This Bash script automates both querying Spot pricing and launching new AWS Spot Instances for intensive Gekkoga workloads.
Please, replace $HOME/AWS/start_aws.sh on your C&C home server with this one:
#!/bin/bash
TYPE=$1
PRICE=$2
REGION=$3
STRAT=`grep "TOLAUNCH=" $HOME/gekko/gekkoga/start_gekkoga.sh | cut -d "\"" -f 2`
ASSET=`grep "ASSETTOUSE=" $HOME/gekko/gekkoga/start_gekkoga.sh | cut -d "\"" -f 2`
if [ "$#" -eq 1 ]; then
echo "Checking ${TYPE} prices ..."
aws ec2 describe-spot-price-history --start-time=$(date +%s) --product-descriptions="Linux/UNIX" --query 'SpotPriceHistory[*].{az:AvailabilityZone, price:SpotPrice}' --instance-types ${TYPE}
else
if [ "$#" -eq 3 ]; then
echo "Requesting a ${TYPE} Spot instance at ${PRICE} ..."
InstanceType=" \"InstanceType\": \"${TYPE}\","
echo ${InstanceType}
sed -i "/InstanceType/c ${InstanceType}" spot_specification.json
AvailabilityZone=" \"AvailabilityZone\": \"${REGION}\""
echo ${AvailabilityZone}
sed -i "/AvailabilityZone/c ${AvailabilityZone}" spot_specification.json
Name="${STRAT} - ${ASSET}"
echo ${Name}
spotInstanceRequestId=`aws ec2 request-spot-instances --spot-price "${PRICE}" --launch-specification file://spot_specification.json --query 'SpotInstanceRequests[0].[SpotInstanceRequestId]' --output text`
echo "Waiting a bit before trying to grab InstanceId from our request ${spotInstanceRequestId} ..."
sleep 5
while [ -z `aws ec2 describe-spot-instance-requests --spot-instance-request-ids ${spotInstanceRequestId} |grep "InstanceId" | cut -d "\"" -f 4` ]; do
echo "Instance still not launched, waiting 5s more ..."
echo "Status is: "
aws ec2 describe-spot-instance-requests --spot-instance-request-ids ${spotInstanceRequestId} |grep "Message" | cut -d "\"" -f 4
sleep 5
done
InstanceId=`aws ec2 describe-spot-instance-requests --spot-instance-request-ids ${spotInstanceRequestId} |grep "InstanceId" | cut -d "\"" -f 4`
echo "Instance created ! InstanceId: ${InstanceId}"
InstanceIP=`aws ec2 describe-instances --instance-ids ${InstanceId} --query 'Reservations[*].Instances[*].PublicIpAddress' --output text`
echo "Public IP: ${InstanceIP}"
aws ec2 create-tags --resources ${InstanceId} --tags "Key=Name,Value=$Name"
echo "Instance ${InstanceId} named: ${Name}"
else
echo "Pass 1 OR 3 parameters:"
echo "\targ1: EC2 instance type (to request its Spot price)"
echo " ex1: ./start_aws.sh c5.4xlarge"
echo " ex2: ./start_aws.sh c5.9xlarge"
echo " ex3: ./start_aws.sh c5.18xlarge"
echo "\targ2: requested price (to launch an instance)"
echo "\targ3: requested region(to launch an instance)"
echo " ex1: ./start_aws.sh c5.4xlarge 0.162 us-east-2a"
echo " ex2: ./start_aws.sh c5.9xlarge 0.325 us-east-2b"
echo " ex3: ./start_aws.sh c5.18xlarge 0.325 us-east-2b"
fi
fiHere’s a breakdown of its core functionalities:
1. Flexible Spot Price Lookup or Instance Launch
- If you call the script with no parameters, it will display some help
- If you call the script with one parameter (instance type):
- It queries and displays the current Spot price for the specified EC2 Instance type across all Availability Zones.
- Useful for quickly checking what Spot price is needed before launching an instance, and also to know the zone names (mandatory to request a VM).
- If you call the script with three parameters (instance type, desired price, and availability zone):
- It automatically edits your
spot_specification.jsonto set the correct instance type and availability zone for your request. - It then sends a Spot Instance request at the specified price using your pre-defined launch configuration file.
- It automatically edits your
2. Automated Instance Tracking and Tagging
- Once the Spot Instance request is sent, the script polls AWS every 5 seconds until the requested instance is actually launched and an
InstanceIdis assigned. - It retrieves the new instance’s public IP address as soon as it’s available.
- The instance is then automatically named after your currently defined strategy and asset (extracted directly from
start_gekkoga.sh), making it easier to track and identify launched instancesin the AWS console.
Key Benefits
- No manual editing: All launch parameters are set on the fly—no more JSON hacks.
- Immediate visibility: See instance status and public IP right after launch.
- Consistency: Instance name reflects running strategy and asset, helping with batch runs and cost tracking.
- Versatility: Use the same script both to monitor spot price trends and to automate instance launching.
Example Usage
- Check current Spot price:
./start_aws.sh c5.4xlarge - Request a new Spot Instance:
./start_aws.sh c5.9xlarge 0.32 us-east-2a
A script to cancel instances requests
You can’t change the parameters of your Spot Instance request, including your maximum price, after you’ve submitted the request. But you can cancel them if their status is either open or active. HEre is a base example for a script which would list your requests, and cancel them.
#!/bin/bash
#get instances requests (2 different ways)
InstanceID=$(aws ec2 describe-spot-instance-requests --query SpotInstanceRequests[*].{ID:InstanceId} | grep ID | cut -d "\"" -f 4)
SpotInstanceRequestId=$(aws ec2 describe-spot-instance-requests --query SpotInstanceRequests[*].{ID:SpotInstanceRequestId} | grep ID | cut -d "\""
#display both lists of requests
echo ${InstanceID}
echo ${SpotInstanceRequestId}
#todo: ajout connexion ssh ec2 et synchro reps logs
#cancel requests
aws ec2 cancel-spot-instance-requests --spot-instance-request-ids ${SpotInstanceRequestId}
Things to remember
- Amazon EC2 will launch your Spot Instance when the maximum price you specified in your request exceeds the actual Spot price and capacity is available in the region you asked. The Spot Instance will run until it is interrupted by Amazon or you terminate it yourself. If your maximum price remains superior or equal to the Spot price, then your Spot Instance will keep running … for a long time, depending on demand. If you forget it, it could cost you a lot !
- As explained in Amazon’s documentation, if a Spot Instance request you made is
activeand has an associated running Spot Instance, canceling the request does not terminate the instance. For more information about terminating a Spot Instance, see Terminate a Spot Instance. - There is NO MORE GUARANTEE that you will earn money now that you automated faster tests on bigger machines. ON THE OTHER HAND WHAT IS SURE AND I CAN GUARANTEE THAT IS INDEED THAT IT WILL COST YOU MORE IN TESTING.
Thoughts & researches about specific parameters to Genetic Algorithms
The standard GekkoGA setting of 7 mutations seems way too much (to me), for a basic strategy which doesn’t has a lot of dynamic parameters to challenge (8 with our MyMACD example in those guides) and a population restricted to 20. In my opinion, it means some parameters will mutate too frequently. Mutations are a good thing but I think we need stability in the gene pool to promote the crossing of good genes, rather than introducing quasi-systematic mutations. Right now, but I need to read more litterature about that and perform more tests, my feeling is that if we want to change so much genes, we also must increase the number of individuals in the population.
The tuning-loop dilemna
I have no ideal setting for GekkoGA. More tests are needed, this is a new challenge. Actually, I’m afraid about the “tuning loop” dilemna with Genetic or Evolutionary Algorithms: using a genetic algorithm to tune the parameters of another algorithm is now common in optimization and machine learning. But it quickly raises a meta-question: how do we choose the right parameters for the Genetic Algorithm itself? Aren’t we just moving the problem up a level?
Why is this a challenge?
Poor parameter tuning leads either to early convergence (local optima) or unnecessarily long calculations for small gains (inefficiency). GA outcome quality depends heavily on its own parameters: population size, mutation rate, crossover rate, number of generations, and more (see below). No “one size fits all”: The optimal settings depend on the problem, encoding, and even on “randomness”—and sometimes on the budget (time/computation power) you have.
GA Generic Parameters & GekkoGA
1. Population Size
- Issue: a population that’s too small can converge too quickly (losing diversity and getting trapped in local optima).
Too large, and it increases computation time without necessarily improving results. - In GekkoGA this is the
populationAmtparameter. It is simply the population size for each generation of the genetic algorithm.- At each “epoch,” this number of individuals (candidate solutions) will be taken into account.
- Practical approach I suggest: start with 30 to 100 individuals, then adjust based on your problem’s complexity. Always test several values.
2. Mutation Rate
- Issue: Too low, and the algorithm won’t explore enough of the solution space; too high, and the GA turns into a random search.
- In GekkoGA, this defines the maximum number of “genes” (strategy parameters) that can be mutated for the “non new randomly generated” individuals during a mutation.
- Exemple: for an individual with 10 parameters/genes, if
mutateElements: 7, then up to 7 parameters can be mutated at the same time, but never more, each time a mutation operation is applied in order to obtain a new population.
- Exemple: for an individual with 10 parameters/genes, if
- Common practice: use an initial mutation rate between 0.5% and 5%. Adaptive mutation strategies (increasing mutation when progress stalls) help maintain diversity and avoid getting stuck in poor solutions. Adaptive mutation is not available in GekkoGA.
3. Introduction of New Genes (Maintaining Diversity)
- Issue: If a population becomes too homogeneous, crossover stops producing new, valuable solutions.
- Solution: regularly inject new randomly generated individuals (“genetic immigration”) or force mutations on some individuals to spur innovation.
- In GekkoGA, the
variationparameter indicates the proportion of “new” individuals (randomly varied) added to the population at each generation of a new population. These new individuals are not the result of crossbreeding or mutation, but are generated “from scratch” according to the rules of the strategy.- Example with populationAmt: 60 and variation: 0.8: 0.8 × 60 = 48 new individuals are randomly created in each generation (the remaining 12 are produced by crossing/mutation of the best individuals from the previous generation).
4. Number of Generations (Epochs)
- Issue: stopping too early leads to suboptimal solutions; too many generations waste computation.
- Best practice: use a stopping criterion (e.g., no improvement after N generations) or a fixed number of generations based on … your experience. Track “fitness” evolution to guide your choice.
5. Classic Pitfalls
- Premature convergence: not enough diversity; the GA quickly settles into a local optimum.
- Overfitting: the GA “learns” the quirks of one specific dataset rather than general patterns (common if there are too many generations or too large a population).
- Computation cost: population and search space size can exponentially increase run times.
6. Best Practices & Modern Strategies
- Test multiple settings and use adaptive parameters (such as dynamic mutation rates).
- Inject diversity on a regular basis.
- Monitor the best score, average population fitness, and genetic diversity at each generation (easy to write… less to do).
- Combine Genetic Algorithms with other optimization approaches (hybrid or local search methods).
How should this dealt with in practice?
- Meta-Optimization (Automated Tuning)
- the principle is to use another layer of optimization (even another GA, Bayesian optimization, or grid/random search) to search for effective GA parameters.
- Yes: it is a “recursion” risk, but in practice, automation + parallelization make it manageable for most real-world problems.
- Tools like Optuna, Hyperopt or even genetic “meta GA” scripts are used for this (sometimes called “hyper-GA” or “meta-GA”). I did not try them.
- Theoretical and Empirical Defaults
- Decades of research and shared experience have produced reasonable defaults for most problems. For example:
- Population size: 30–100 (for many economic/engineering problems)
- Mutation/crossover: 1–5% mutation, 60–90% crossover
- Generation count: problem-dependent, but often until stagnation or a max value
- Many practical applications simply run a few experiments to fine-tune these few high-level meta-parameters.
- This is the “parameter sweep” technique: we simply run a few trials (runs) with different values to select the most effective ones. Unlike more advanced methods (Bayesian, evolutionary), parameter sweep is a systematic, basic approach that is often sufficient in practice.
- Decades of research and shared experience have produced reasonable defaults for most problems. For example:
- Adaptive and Self-Tuning GAs
- Some advanced GAs (not GekkoGA unfortunately) adapt their parameters during runtime—e.g., increasing mutation rate if progress stalls or adjusting selection pressure according to diversity.
- This tries to break the “snake eating its tail” loop by letting the algorithm tune itself on the fly.
Conclusion & Further Reading
Automating large-scale backtesting with Gekkoga on EC2 Spot Instances opens up tremendous possibilities for quantitative analysis—at the cost of careful engineering and thoughtful parameter tuning.
AWS Spot infrastructure lets you “brute-force” thousands of strategy candidates at previously unaffordable speeds, but only if you also automate shutdown handling and data preservation.
Key Takeaways
- High-CPU Spot Instances can drastically accelerate your GA-based strategy optimization, provided you tune both your infrastructure and your genetic algorithm parameters.
- There are no universal GA settings; population size, mutation/crossover rate, and diversity mechanisms all need empirical adjustment. This is a whole field of research.
- Automating notifications, result syncing, and resource cleanup turns a fun experiment into a robust production tool.
Some Challenges Remain
- The “parameter tuning loop” dilemma: optimizing GA parameters without falling into an endless meta-tuning spiral.
- AWS billing: running oversized machines longer than needed will increase costs—always monitor usage and automate instance cleanup!
Recommended Literature & Resources
- Genetic Algorithm Parameters, Tuning & Diversity:
- Optimizing Genetic Algorithms for Time Critical Problems (PDF) – Complete academic overview of parameter tuning, including adaptive mutation.
- Your 8 Advanced Tips to Optimize Genetic Algorithms – Practical, illustrated advice for modern GA use.
- Wikipedia: Algorithme génétique (français) – French introduction, with focus on population/diversity.
- Mutation Strategies Analysis – Best practices for balancing mutation rates and population.
- A New Strategy for Adapting the Mutation Probability in GAs (PDF) – For those wanting to implement self-adaptive mutation.
- AWS & Automation:
- Internal blog links for advanced topics:
If you have comments, corrections, or experience from your own experiments (good or bad!), please share below or contact me directly. Continuous improvement is the heart of evolutionary approaches—and of community knowledge!
nice article, i do remind that the inventer of gekko, also noted that it isnt optimal for small candle sizes. I’ve noticed most neural nets behave terrible with short times as well. On the other hand, i think candles can be added as well (5+5=10min candle), so then it just comes then down to optimal smoothing effects / while one would think a good algorithm would finds profit in all time smooth ranges; and if it doesnt, then the algorythm just is a ‘randomly-data’ best fit. (ea it wont work as good if you change the times ranges, or time scales. It just happened to be a fit for that specific graph.
In those cases we lack the knowledge of what we do, and try random fits of math..