Dans les tutoriels précédents, nous avons vu comment installer Gekko, utiliser ses fonctionnalités principales et créer votre première stratégie personnalisée. Dans cet article, nous allons nous concentrer sur l’optimisation de vos stratégies grâce au backtesting automatique des paramètres avec Gekkoga, et les algorithmes génétiques.
Avantages du backtesting automatisé
Chaque stratégie, qu’il s’agisse de votre propre code personnalisé ou d’un code trouvé en ligne affichant d’excellents résultats de backtesting, doit être adaptée à votre marché, votre devise et vos actifs spécifiques. Cela signifie que vous devez trouver les paramètres adaptés à votre situation particulière. Vous devrez effectuer de nombreux backtests, puis des tests sur le marché réel avec des ordres simulés (mode paperTrader), avant de vous lancer « en direct ».
Gardez à l’esprit que même si vous découvrez les paramètres parfaits pour le backtesting (ceux qui offrent le profit et le ratio de Sharpe les plus élevés), cela ne garantit pas des résultats similaires en temps réel, car les tendances et les volumes réels du marché ne peuvent être prédits à l’avance. Si seulement c’était aussi simple ! Les outils décrits ici ont une limite fondamentale : ils peuvent vous aider à trouver les meilleurs paramètres pour votre stratégie à partir de données historiques, mais cela ne garantit pas les performances futures (voir overfitting – surajustement ou ajustement de courbe).
Donc, tout d’abord, nous devons définir une bonne stratégie de backtest, quelle que soit la manière (automatisée ou non) dont nous allons trouver et tester les paramètres. À mon avis, une bonne stratégie de test (c’est ce qui se fait dans les phases d’apprentissage et de test en IA générative) consiste à diviser votre ensemble de données de backtest en plusieurs parties : un long ensemble de données pour effectuer un backtest général et obtenir un bon profit et un bon ratio de Sharpe, puis le tester sur des ensembles de données plus petits, bien sûr toujours issus du même marché/de la même devise/du même actif, mais avec différents types de tendances. De cette façon, vous serez en mesure de:
- comprendre comment la stratégie fonctionnera avec les paramètres X ou Y sur tel ou tel type de tendance,
- voir comment les paramètres optimaux varient selon les différentes conditions du marché.
Grâce à ce type de résultats et de connaissances, nous pourrions imaginer mettre en œuvre une stratégie qui modifierait et adapterait automatiquement ses paramètres (voire les indicateurs utilisés) à la tendance actuelle, s’il s’agit d’une tendance à long terme.
Dans tous les cas, chaque « bon » test devrait nécessiter une analyse manuelle plus approfondie de votre part : vous devrez étudier chaque transaction: quand ont-elles été effectuées ? Sont-elles appropriées ou non ? Les pertes importantes ont-elles été contrôlées par la mise en place d’un stop-loss ou non ? Si vous modifiez légèrement un paramètre, cela ne rendra-t-il votre stratégie un peu moins rentable sur votre ensemble de données passées, mais aussi moins risquée et plus rentable pour l’avenir ? La clé principale est probablement de contrôler les pertes importantes sur le marché. Ensuite, d’ajouter quelques bonus à la stratégie.
Revenons à ce chapitre : je souhaitais compléter mes études théoriques sur divers indicateurs (afin de mieux les comprendre et, à terme, trouver une manière appropriée de les combiner) par des outils techniques permettant d’améliorer la phase de backtesting. Lorsque je teste une stratégie, je dois la tester de nombreuses fois ; j’ai donc naturellement cherché des outils qui me permettraient d’automatiser cette tâche, et j’ai trouvé, entre autres, Gekkoga, un outil d’entraînement aux algorithmes génétiques (AG). Il automatise la recherche des paramètres optimaux d’une stratégie de trading, mais sur un unique dataset en revanche, ce qui est déjà bien pour démarrer.
Comment fonctionne Gekkoga ?
Le moteur sous-jacent de GekkoGA est genetic-js, un moteur/bibliothèque d’algorithmes génétiques JavaScript. Il s’agit d’un framework GA flexible et modulaire pour Node.js, prenant en charge des fonctions d’aptitude personnalisées, divers schémas de sélection/croisement/mutation, l’élitisme, et plus encore.
Comment genetic-js est-il utilisé dans Gekkoga ?
Gekkoga « encapsule » genetic-js et appelle l’API de Gekko pour lancer des backtests, fournissant :
- Encodage de problème: chaque individu/solution dans la population est un ensemble de paramètres de stratégie Gekko, encodés sous forme de chromosome.
- Fonction de fitness : La valeur de fitness de chaque individu est calculée en effectuant un backtest dans Gekko et en évaluant le résultat (généralement en fonction de la performance, du risque, du drawdown, etc.).
- Operateurs:
- Sélection : détermine quels individus (ensembles de paramètres) reproduiront la génération suivante, généralement en fonction du classement de fitness.
- Croisement : combine deux individus parents pour créer une solution enfant (en mélangeant les paramètres/chromosomes).
- Mutation : modifie de manière aléatoire certains paramètres/chromosomes d’un individu afin de maintenir la diversité et d’explorer l’espace de recherche.
Comme nous le verrons dans un prochain article, avec les algorithmes génétiques, la gestion de la population est essentielle : contrôle du nombre d’individus, taux d’introduction de variations et de remplacement générationnel (qui a dit que c’était pareil dans les sociétés ?).
Paramètres
Par défaut, nous pourrons facilement régler des paramètres tels que :
populationAmt(taille de la population),variation(proportion de nouveaux individus aléatoires par génération),mutateElements(nombre maximal de paramètres modifiés par individu).
Nous devrons également rechercher si nous pouvons modifier :
- La méthode de sélection (par exemple, tournoi, élitisme)
- La fonction Fitness, qui est par défaut basée sur le profit, le drawdown ou un score combiné.
Algorithme général
Son algorithme très macro est le suivant :
- Étape 1 : Génération des paramètres
- Gekkoga commence par générer une population d’ensembles aléatoires de paramètres pour la stratégie Gekko que vous avez choisie (par exemple : MACD court/long/signal, seuils, stop loss, etc.).
- Étape 2 : Backtesting
- Pour chaque ensemble de paramètres défini dans la population, Gekkoga utilise l’API de Gekko pour effectuer un backtest sur l’ensemble de données que vous avez sélectionné. Il enregistre des indicateurs de performance tels que le profit et le ratio de Sharpe.
- Étape 3 : Epochs et sélection
- Une fois tous les backtests de la population actuelle terminés (ce que l’on appelle une epoch ou génération), Gekkoga sélectionne les ensembles de paramètres les plus performants. Ceux-ci sont considérés comme les « gagnants » de la génération.
- Étape 4 : Évolution — Croisement et mutation
- Les gagnants sont ensuite utilisés pour produire une nouvelle génération d’ensembles de paramètres en combinant (croisement) et en modifiant aléatoirement certaines valeurs (mutation). Cela simule la sélection naturelle et l’évolution génétique.
- Étape 5 : itération
- Ce processus (génération, backtesting, sélection et évolution des paramètres) se répète pendant plusieurs epochs/générations. Au fil du temps, les ensembles de paramètres s’améliorent généralement et convergent vers les valeurs optimales pour votre ensemble de données.
- Arrêt et résultats
- Vous pouvez arrêter l’optimisation quand vous le souhaitez ou la laisser fonctionner jusqu’à ce que les améliorations stagnent (personnellement, j’ai toujours dû interrompre Gekkoga manuellement). Gekkoga exporte les meilleurs résultats trouvés au format JSON pour une analyse plus approfondie.
En bref, Gekkoga automatise entièrement le processus d’ajustement par essais et erreurs des stratégies Gekko, en utilisant des techniques évolutives pour optimiser les paramètres avec une intervention humaine minimale. Pour plus de détails et pour la configuration avancée, consultez le projet GitHub Gekkoga.
Étape 1 : Installation de Gekkoga
Passons à l’installation. Elle est simple, mais nécessite une configuration Gekko entièrement fonctionnelle. N’essayez pas d’utiliser Gekkoga si vous ne disposez pas déjà d’une installation Gekko opérationnelle et si vous ne maîtrisez pas encore son utilisation, sinon la recherche d’erreur sera un calvaire (expérience vécue). Nous allons installer Gekkoga dans le répertoire d’accueil de Gekko (dans ce guide, j’ai cloné mon répertoire d’installation « gekko » habituel dans un deuxième répertoire « gekkoga »).
cd <gekko_installdir>
git clone https://github.com/gekkowarez/gekkoga.git
cd gekkoga
Nous devons maintenant déployer un correctif apporté pour rendre Gekkoga compatible avec la dernière version Gekko v0.6x que nous avons installée précédemment, car certaines modifications ont été apportées à son API.
git fetch origin pull/49/head:49
git checkout 49
Nous téléchargeons manuellement un correctif dans index.js pour prendre en charge les paramètres imbriqués de Gekko et corriger un problème dans les mutations.
mv index.js index.js.orig
curl -L -O https://raw.githubusercontent.com/gekkowarez/gekkoga/stable/index.js
Nous téléchargeons manuellement un correctif dans package.json pour prendre en charge les paramètres de configuration imbriqués.
mv package.json package.json.orig
curl -L -O https://raw.githubusercontent.com/gekkowarez/gekkoga/stable/package.json
Ensuite, nous l’installons. Encore une fois, attention : n’exécutez pas « npm audit fix » comme suggéré à la fin de la commande npm install ci-dessous, cela causerait des dysfonctionnements.
npm install
Remarque : Gekkoga aura besoin soit d’une version « complète » de Gekko ou « simplement » sa partie interface utilisateur (utilisez le script de démarrage PM2 start_ui.sh que nous avons créé dans l’article sur l’installation de Gekko), ou le serveur API qui se trouve dans <gekko_installdir>/web, et il en fera un usage intensif. C’est pourquoi, dans l’article sur l’installation de Gekko, j’ai recommandé d’augmenter les délais d’attente par défaut dans <gekko_installdir>/web/vue/dist/UIconfig.js et dans
<gekko_installdir>/web/vue/public/UIconfig.js à 600000.
Étape 2 : Configuration de Gekkoga
Créer un fichier de configuration spécifique
Le fichier de configuration de Gekkoga se trouve dans <gekko_installdir>/config/. Nous allons copier le fichier d’origine dans un nouveau fichier dédié au backtest de notre stratégie personnalisée (MyMACD) et créer un lien symbolique avec le nom du fichier de configuration que nous avons défini dans le script start.sh. Cela nous facilitera la tâche plus tard, lorsque nous aurons de nouvelles stratégies à backtester : il nous suffira de copier dans gekkoga/config un fichier de configuration dont le nom contiendra le nom de la stratégie utilisée, et de mettre à jour le lien symbolique config/config-backtester.js pour qu’il pointe vers ce fichier de configuration spécifique.
cp <gekko_installdir>/gekkoga/config/sample-config.js <gekko_installdir>/gekkoga/config/config-MyMACD-backtester.js
ln -s
<gekko_installdir>/gekkoga/config/config-MyMACD-backtester.js
<gekko_installdir>/gekkoga/config/config-backtester.js
Modifier le fichier de configuration pour refléter les paramètres de base de Gekko.
Nous allons maintenant modifier <gekko_installdir>/gekkoga/config/config-MyMACD-backtester.js. Ce n’est pas compliqué, MAIS nous devrons définir EXACTEMENT les mêmes paramètres que dans votre fichier de configuration gekko ou votre fichier toml. Sinon, Gekkoga démarrera, mais sans effectuer aucune transaction si quelque chose ne va pas. Faites attention aux fautes de frappe, aux types de données que vous utiliserez et à leur type (entier ou flottant) et aux éventuelles décimales.
N’oubliez pas : la cohérence entre les fichiers de configuration est essentielle pour garantir le bon fonctionnement de Gekkoga.
Astuce : essayez d’utiliser autant que possible des nombres entiers dans vos paramètres de stratégie et évitez les nombres à virgule flottante lorsque cela est possible. C’est pourquoi, dans notre Strat MACD personnalisée, j’ai défini le pourcentage de stop loss comme un nombre entier, puis dans MyMACD.js, lorsque nous devons l’utiliser, nous le divisons par 100. Si nous avions utilisé un nombre à virgule flottante pour permettre un stop loss très précis, cela nous aurait obligés à demander à Gekkoga de générer des nombres à virgule flottante aléatoires, et même si nous pouvons forcer une limite au nombre de décimales utilisées, le nombre de combinaisons possibles et les backtests à effectuer seraient exponentiels. De plus, le .toFixed(2) que nous utilisons parfois dans le fichier de configuration Gekkoga pour forcer un nombre de décimales est un artefact : la bibliothèque utilisée pour générer les nombres aléatoires génère en fait des nombres flottants avec une précision bien supérieure à 2 décimales, puis les tronque ou les arrondit artificiellement à 2 chiffres. Cela signifie que Gekkoga effectuera en effet de nombreux backtests avec le même nombre flottant arrondi à 2 chiffres, car les nombres flottants qu’il a réellement générés en arrière-plan n’étaient en fait pas égaux (ex. 2.00004 et 2.00577 seront tous les deux arrondis à 2.00 mais considérés comme deux individus différents).
Conseil : évitez autant que possible d’utiliser des flottants pour les paramètres, car un nombre trop élevé de décimales augmentera de manière exponentielle le nombre de combinaisons de backtests.
Nous modifions d’abord la section config, afin qu’elle reflète EXACTEMENT notre fichier de configuration gekko. Mêmes paramètres, mêmes valeurs.
const config = {
stratName: 'MyMACD',
gekkoConfig: {
watch: {
exchange: 'kraken',
currency: 'EUR',
asset: 'ETH'
},Nous utilisons la fonctionnalité de scan pour exploiter automatiquement l’intégralité de l’ensemble de données à utiliser ; pour l’instant, nous souhaitons tester Gekkoka sur l’ensemble de données complet. Plus tard, lorsque nous saurons que Gekkoka fonctionne, vous pourrez modifier cela afin de réduire l’ensemble de données et refléter la stratégie de test que j’ai expliquée précédemment (test par rapport à des segments/tendances spécifiques).
daterange: 'scan', /* daterange: { from: '2018-01-01 00:00', to: '2018-02-01 00:00' }, */
Nous mettons maintenant à jour notre solde et les frais afin que les tests puissent commencer à simuler les transactions. Vous vous souvenez de mon ancien conseil ? Même si je ne suis pas sûr que Gekko l’utilise réellement lorsqu’il simule des transactions, je recommande d’augmenter le slippage afin de mieux refléter ce qui se passe sur le marché réel : lorsque vous passez un ordre, son exécution prend du temps, et pendant ce temps, la valeur de l’actif que vous négociez fluctue.
Conseil : il doit s’agir d’une valeur décimale : pour un taux de slippage de 5 %, vous devez écrire 0,05, et pour un taux de 0,1 %, vous devez écrire 0,001.
simulationBalance: { 'asset': 0, 'currency': 100 //note that I changed this since initial confs in other posts }, slippage: 0.05, feeTaker: 0.16, feeMaker: 0.26, feeUsing: 'taker', // maker || taker
L’apiURL devrait fonctionner si vous avez suivi mes guides précédents.
apiUrl: 'http://localhost:3000',
Ajustez les capacités de calcul parallèle de Gekkoga à votre CPU
Nous ne modifierons pas, pour l’instant, les paramètres standard populationAmt, variation, mutateElements, minSharpe ou mainObjective.
parallelqueries doit en revanche être mis à jour pour refléter la configuration de votre processeur, car il s’agit du nombre de backtests parallèles que Gekkoga pourra lancer. Plus vous utilisez de processeurs, mieux c’est. Mais vous devez absolument aligner ce nombre sur le nombre réel de processeurs disponibles. Si vous disposez de 4 processeurs ou vCPU, utilisez 3 ou 4 au maximum. Avec 4, toute la capacité de votre CPU sera utilisée par Gekkoga, ce qui pourrait rendre votre ordinateur presque inutilisable pour d’autres tâches pendant que Gekkoga est en cours d’exécution (et le ventilateur de votre CPU commencera à faire du bruit). Si vous disposez d’un ordinateur dédié à Gekoga, cela ne pose pas de problème, mais si ce n’est pas le cas, cela peut poser un problème, alors envisagez une valeur inférieure. C’est à vous de décider.
Dans mon cas,
- Sur mon ordinateur portable habituel, j’ai un processeur à deux cœurs, mais le système d’exploitation en détecte quatre grâce à la technologie Hyper-Threading. J’en utiliserai donc trois, car je souhaite garder un processeur disponible pour d’autres tâches.
- Au moment où j’écris cet article, j’ai essayé d’exécuter Gekkoga sur un Amazon EC2 t2.micro (un seul vCPU) avec ce paramètre réglé sur 1, j’ai perdu le contrôle de la VM et j’ai dû la redémarrer ;
- Pour ce test, je vais le lancer sur mon Intel NUC dans une machine virtuelle équipée de 2 vCPU, mais je vais conserver le paramètre à 1 afin de ne pas trop le solliciter, car un NUC n’est pas conçu pour des calculs CPU intensifs (je crains que le ventilateur ne refroidisse pas suffisamment le boîtier et le CPU).
parallelqueries: 1,
Configurer les notifications par e-mail de Gekkoga
Si vous souhaitez recevoir des notifications par e-mail, vous pouvez activer la section correspondante :
// optionally recieve and archive new all time high every new all time high
notifications: {
email: {
enabled: false,
receiver: 'xxx.yyy@gmail.com',
senderservice: 'gmail',
sender: 'xxx.yyy@gmail.com',
senderpass: '<passkey you have to configure on gmail>',
},
},
Configurer les plages de valeurs à tester
Nous entrons maintenant dans la partie intéressante. Nous allons expliquer à Gekkoga tous les paramètres dont nous avons besoin pour notre stratégie, ainsi que leurs valeurs. Si vous entrez une valeur fixe, Gekkoga utilisera cette valeur à chaque fois, dans chaque backtest. Elle ne changera pas. Mais nous pouvons également définir :
- Certaines plages de valeurs spécifiques, à l’aide de tableaux, par exemple [5,10,15,30,60,120,240]
- Ses choix aléatoires seront alors limités à 5, 10, 15, 30, 60, 120 ou 240.
- Utile par exemple pour effectuer des backtests avec différentes tailles de bougies…
- Des valeurs aléatoires, en utilisant des fonctions telles que randomExt.integer(max, min) ou randomExt.float(max, min).toFixed(2)
- Il choisira un nombre entier aléatoire compris entre min et max, ou un nombre à virgule flottante aléatoire compris entre min.00 et max.00.
Rappel: avez-vous remarqué le .toFixed(2) pour les plages de flottants ? Il force le flottant aléatoire à être arrondi à 2 décimales et c’est cette valeur arrondie qui sera utilisée dans le backtest de Gekko. Mais gardez à l’esprit que le nombre flottant sera toujours généré avec un nombre de chiffres plus élevé, et que 2,0003 ou 2,0004 seront dans les deux cas arrondis à 2,00. Cela conduira à des backtests en double. C’est pourquoi je vous recommande d’utiliser autant que possible des nombres entiers plutôt que des nombres flottants.
Tout d’abord, les valeurs des bougies. Je ne suis pas vraiment convaincu par l’utilisation de bougies courtes, mais comme l’outil va les tester pour nous, pourquoi ne pas essayer ?
candleValues: [5,15,30,60,120,240,480,600,720],
Maintenant, les paramètres stratégiques spécifiques… Notez mon optimisation: j’ai commenté les plages flottantes pour les seuils haut et bas, et les ai remplacées par des nombres entiers que je divise par 100.
getProperties: () => ({ historySize: randomExt.integer(50, 1), short: randomExt.integer(30,5), long: randomExt.integer(100,15), signal: randomExt.integer(20,6), thresholds: { //up: randomExt.float(20,0).toFixed(2), //down: randomExt.float(0,-20).toFixed(2), up: randomExt.integer(400,1)/100, down: randomExt.integer(1,-400)/100, persistence: randomExt.integer(9,0), stoploss: randomExt.integer(50,0), }, candleSize: randomExt.pick(config.candleValues) })
Étape 3 : Tests et backtests
Avant de lancer Gekkoga, n’oubliez pas que vous devez avoir une instance de Gekko en cours d’exécution en arrière-plan, même si elle ne fait absolument rien (pour l’instant). L’objectif est que l’API de Gekko soit prête à recevoir les appels de Gekkoga afin de lancer les backtests. Dans mon cas, j’ai créé un script simple dans le répertoire d’accueil de Gekko, qui lancera une instance de Gekko appelée « gekko_ui ». Voir mon article précédent.
Une fois votre instance gekko lancée, essayons Gekkoga… Nous devrons vérifier attentivement les informations de la console.
gekko@bitbot:~/gekkoga/gekkoga$ node run.js -c config/config-MyMACD-backtester.js No previous run data, starting from scratch! Starting GA with epoch populations of 20, running 1 units at a time! node run -c config/config-MyMACD-backtester.js
Youpi ! Ça a démarré. Maintenant, je l’arrête (CTRL-C) et je vais créer un joli script de démarrage PM2, car je veux pouvoir le faire tourner facilement en arrière-plan et obtenir facilement des informations à son sujet.
echo #!/bin/bash > start.sh echo "rm logs/*" >> start.sh echo "pm2 start run.js --name gekkogaMyMACD --log-date-format="YYYY-MM-DD HH:mm Z" -e logs/err.log -o logs/out.log -- -c config/config-MyMACD-backtester.js max_old_space_size=8192 >> start.sh chmod 755 start.sh
Nous le redémarrons à l’aide de ce script…
./start.sh
pm2 ls

Vérifions ses journaux…

Il fonctionne en arrière-plan, très bien. Jetons maintenant un œil aux journaux de l’interface utilisateur de Gekko, car il est censé recevoir des appels API de Gekkoga :
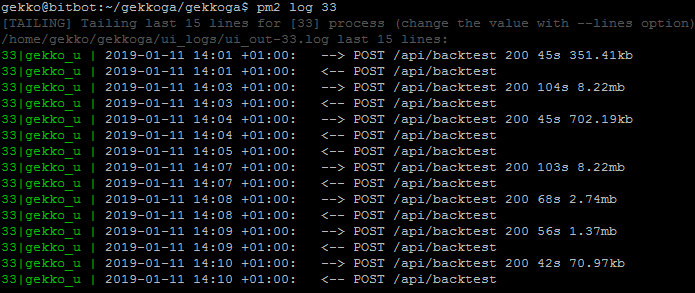
Nous pouvons voir quelques appels à l’API de backtest, parfait. Maintenant, vérifions d’autres informations, pendant que nous attendons les premiers résultats :
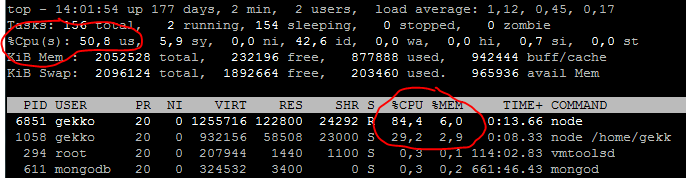
Conclusion : Gekkoga sollicite fortement l’un des deux processeurs utilisés par cette machine virtuelle, ce qui correspond à ce que nous avons défini dans la configuration. La consommation de mémoire est faible.
Et enfin, 21 minutes plus tard, la première époque s’est achevée :

Vous trouverez une explication de ce qu’est une epoch/génération ici. Ce que nous voyons ici, c’est le gagnant de cette epoch, et Gekkoga continue de fonctionner pour calculer davantage et les comparer. Il enregistre la meilleure combinaison trouvée dans <gekkoga_installdir>/results au format JSON. Pour l’afficher, nous utiliserons l’utilitaire jq (exécutez « apt-get install jq » en tant qu’administrateur si vous ne l’avez pas encore) :
cat results/config-MyMACD-backtester-EUR_ETH.json | jq

Nous voyons donc ici que le gagnant pour l’instant a utilisé une valeur longue de 65, une valeur courte de 29, une valeur de signal de 9, une taille de bougie de 5 minutes (ce qui me blesse profondément 🙂 C’est vraisemblablement de l’overfitting), une taille d’historique de 15 bougies, un seuil à la hausse de 2,44, un seuil à la baisse de -2,13, un stop loss de 16 % et une persistance de 0. Notre fichier de configuration Gekkoga utilisant uniquement des nombres entiers est bien formaté !
Maintenant, le Sharpe est très élevé (ce qui peut paraître étrange, voir le chapitre ci-dessous), mais en termes de bénéfices estimés, sur l’ensemble de cet échantillon, nous avons en fait obtenu de meilleurs résultats (1101 %) que le marché (817 %), avec 68 transactions.
Le problème, c’est que cela va prendre très très… très… longtemps. Pour l’instant, je n’ai pas grand-chose d’autre à dire, nous devons attendre. En attendant, nous pouvons continuer à approfondir nos connaissances sur les indicateurs et leur fonctionnement, et imaginer des améliorations à apporter à notre stratégie.
La seule façon d’optimiser le temps d’exécution semble être d’exécuter Gekkoga & Gekko sur davantage de processeurs et d’adapter le paramètre parallelqueries. Je ne l’ai jamais fait auparavant, mais cela m’a donné l’idée d’essayer de le faire fonctionner sur une machine Amazon EC2. Ceci sera détaillé dans un autre article.
Un mot sur le ratio « Sharpe »
Qu’est-ce que le ratio de Sharpe ?
Sharpe est un économiste. Son ratio mesure la performance d’une stratégie d’investissement ajustée en fonction du risque. Il répond à la question « Quel est le rendement excédentaire obtenu (par rapport à un taux sans risque) pour chaque unité de risque prise ? ». Un ratio plus élevé implique un rendement plus élevé par rapport au niveau de risque de l’investissement. (source)
Formule classique : Sharpe = (rendement du portefeuille – taux sans risque) / volatilité
Rendement du portefeuille: rendement de la stratégie (généralement annualisé)Taux sans risque: taux sans risque (souvent utilisé: le taux des obligations d’État à court terme)Volatilité: volatilité (écart type) des rendements de la stratégie
→ Plus le Sharpe est élevé, plus votre stratégie est efficace pour générer un rendement par unité de risque. Il s’agit d’un indicateur essentiel pour comparer les stratégies, car il tient compte à la fois de la performance et de la volatilité.
L’implémentation du ratio de Sharpe dans Gekko
Dans Gekko, le ratio de Sharpe est calculé dans le plugin performanceAnalyzer. La logique exacte (code dans plugins/performanceAnalyzer/performanceAnalyzer.js) est la suivante :
const sharpe = (relativeYearlyProfit - perfConfig.riskFreeReturn)
/ statslite.stdev(this.roundTrips.map(r => r.profit))
/ Math.sqrt(this.trades / (this.trades - 2));Signification :
- relativeYearlyProfit: rendement annualisé de votre stratégie après backtest
- perfConfig.riskFreeReturn : le taux sans risque défini dans la configuration
- statslite.stdev(this.roundTrips.map(r => r.profit)): écart type des profits par aller-retour (c’est-à-dire les transactions d’achat et de vente complètes)
- Math.sqrt(this.trades / (this.trades – 2)) : Correction de Bessel (pour les petits échantillons)
La valeur utilisée pour perfConfig.riskFreeReturn dans Gekko provient directement de votre fichier de configuration (sample-config.js). Vous la trouverez dans la section configuration, généralement comme suit :
config.performanceAnalyzer = {
enabled: true,
riskFreeReturn: 5
}- riskFreeReturn est le taux annuel sans risque (en pourcentage) que vous définissez dans la configuration Gekko. Si vous définissez
riskFreeReturn: 5, le bot utilisera la valeur 5 (soit 5 % par an) dans le calcul du ratio de Sharpe.
Le ratio de Sharpe dans Gekko est un ratio de Sharpe annuel calculé à partir des « allers-retours » réels effectués par la stratégie pendant le backtest, comme le recommande la littérature financière. Cela vous permet de comparer directement les « rendements ajustés au risque » de vos stratégies Gekko, et pas seulement leurs bénéfices bruts.
Remarque (très importante) : un Sharpe extrêmement élevé (>2-3) dans le backtest peut être le signe d’un surajustement (overfitting) ou de données irréalistes — vérifiez toujours les résultats sur d’autres échantillon ou en temps réel (paper Trading).
Conclusion et prochaines étapes
L’automatisation du backtesting de votre stratégie Gekko avec Gekkoga est un grand pas en avant vers la création d’algorithmes de trading plus robustes, plus efficaces et plus rentables. Cependant, n’oubliez jamais :
- Vérifiez vos résultats pour détecter tout signe de surajustement (overfitting);
- Tester sur divers ensembles de données et tendances de marché ;
- Consacrez du temps à vous informer sur les indicateurs sous-jacents et les techniques de gestion des risques (y compris les stop-loss robustes).
Lectures complémentaires :
- How to Customize a Gekko Strategy (Step-by-Step Guide)
- Gekko Trading Bot Installation
- How to Safely Use the Gekko Trading Bot: From Backtest to Real Trading
- Running Gekkoga on Amazon EC2