Nous avons appris comment lancer une instance EC2 à partir d’une AMI Amazon avec un déploiement automatisé de l’application/configuration gekko/gekkoga. Nous allons maintenant apprendre à l’utiliser sur une instance plus puissante, avec un plus grande nombre de processeurs et à un prix avantageux (fonctionnalité Amazon EC2 Spot), afin de pouvoir littéralement tester rapidement tous les paramètres et entrées possibles d’une stratégie de trading donnée, à l’aide de l’algorithme génétique de Gekkoga.
Les principaux documents que nous utiliserons :
- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-requests.html
- https://aws.amazon.com/ec2/spot/pricing/
Étape 1 : associer un nouveau rôle IAM AWSServiceRoleForEC2Spot
Comme expliqué dans la documentation d’Amazon, nous devons d’abord créer un nouveau rôle AWSServiceRoleForEC2Spot dans notre console Web AWS. Cela ne nécessite que quelques clics, veuillez lire leur documentation :
En utilisant la console
- Ouvrez la console IAM à l’adresse https://console.aws.amazon.com/iam/.
- Dans le volet de navigation, sélectionnez Rôles.
- Choisissez Créer un rôle.
- Sur la page « Sélectionner le type d’entité de confiance » (Select type of trusted entity page), choisissez EC2, EC2 – Instances Spot, Suivant : Autorisations (Next: Permissions).
- À la page suivante, sélectionnez Suivant : Révision (Next:Review).
- Sur la page Révision (Review), sélectionnez Create role (Créer un rôle).
En utilisant votre CLI ec2
aws iam create-service-linked-role --aws-service-name spot.amazonaws.comÉtape 2 : gestion de l’arrêt automatique des machines virtuelles Amazon pour les instances Spot
Ensuite, nous devons nous occuper de l’arrêt automatique des instances Spot par Amazon, car celui-ci dépend du prix du marché ou de la durée d’utilisation fixe que vous avez spécifiée dans votre demande d’instanciation. Lorsque Amazon décide d’arrêter une instance, il envoie une notification technique à la VM, que nous pouvons surveiller et interroger à l’aide d’un point de terminaison (une URL). Oui, cela signifie que nous devrons intégrer un nouveau script dans notre AMI de référence EC2 afin de gérer un tel événement d’arrêt et de lui faire exécuter les actions appropriées avant l’arrêt de la VM.
Remarque : Amazon annonce un délai de deux minutes entre la notification de résiliation et l’arrêt effectif. Ce délai est court.
La méthode que j’ai choisie (mais il en existe d’autres) consiste à lancer un script récurrent « en arrière-plan » au démarrage de la VM via notre rc.local déjà modifié. Ce script interroge toutes les 5 secondes les métadonnées appropriées à l’aide d’un appel curl. Si les métadonnées correctes sont fournies par Amazon, nous exécutons alors un script d’arrêt personnalisé. Ce script d’arrêt doit donc être intégré dans le package personnalisé que notre VM téléchargera automatiquement depuis notre serveur de référence au moment du démarrage.
Maintenant, nous démarrons une nouvelle VM basée sur notre dernière AMI. Nous insérons ces 3 nouvelles lignes juste avant la dernière instruction « exit 0 » dans le fichier /etc/rc.local de la VM :
echo "Launching background script to handle termination events ..."
/etc/rc.termination.handling &
echo "Done."Ensuite, nous créons un script /etc/rc.termination.handling, basé sur les indications fournies dans la documentation d’Amazon. Veillez à modifier les lignes 17, 19, 20 et 22 afin que vos résultats Gekkoga et divers journaux soient synchronisés dans un répertoire horodaté :
#!/bin/bash
while true; do
if curl -s http://169.254.169.254/latest/meta-data/spot/instance-action | grep -q -E 'stop|terminate|hibernate'
#for testing shutdown script
# if curl -s http://169.254.169.254/latest/meta-data/spot/instance-action | grep -q -E '404'
then
d=$(date +%Y%m%d_%H%M%S)
#logging in a timestamped shutdown log file and in console
exec >> >(tee /home/ec2-user/AWS/logs/${d}_shutdown.log|logger -t user-data -s 2>/dev/console) 2>&1
echo "Received a termination notification on $d"
echo "Launching termination commands"
# stopping pm2 process (ui & Gekkoga. Nota we should better use their names instead of theorical id)
su ec2-user -c "pm2 stop 1 2"
# archival of the results in a timestamped dir
su ec2-user -c "cd /home/ec2-user && cp -R gekko/gekkoga/results AWS/results/${d}_results"
# create the same timestamped dir on our reference server @home
ssh <YOUR_C&C_SERVER> "mkdir /home/gekko/AWS/results/${d}_results"
# upload the results on our reference server @home in two different places
scp -r /home/ec2-user/AWS/results/${d}_results/* <YOUR_C&C_SERVER>:/home/gekko/AWS/results/${d}_results
scp -r /home/ec2-user/AWS/results/${d}_results/* <YOUR_C&C_SERVER>:/home/gekko/gekko/gekkoga/results
# archive the shutdown logs on our reference server
scp -r /home/ec2-user/AWS/logs/${d}_shutdown.log <YOUR_C&C_SERVER>:/home/gekko/AWS/logs
echo "Done."
echo "===== End of Gekko Termination script ====="
break
fi
sleep 5
doneNous le rendons exécutable :
sudo chmod u+x /etc/rc.termination.handlingNous allons maintenant vérifier si cela fonctionne. La seule chose que nous ne pouvons pas tester pour l’instant est le point de terminaison URL réel avec les informations de terminaison. Tout d’abord, nous redémarrons notre machine virtuelle EC2 de référence et nous vérifions que notre script rc.termination.handling s’exécute en arrière-plan :

Nous allons maintenant tester son exécution, mais nous devons légèrement modifier son déclencheur, car notre VM n’est pas encore une instance Spot et l’URL que nous vérifions ne contient aucune information de résiliation, ce qui entraînera une erreur 404. J’ai également désactivé la boucle afin qu’elle ne s’exécute qu’une seule fois.
#!/bin/bash
# while true; do
# if curl -s http://169.254.169.254/latest/meta-data/spot/instance-action | grep -q -E 'stop|terminate|hibernate'
# for testing shutdown script
if curl -s http://169.254.169.254/latest/meta-data/spot/instance-action | grep -q -E '404'
then
d=$(date +%Y%m%d_%H%M%S)
#logging in a timestamped shutdown log file and in console
exec >> >(tee /home/ec2-user/AWS/logs/${d}_shutdown.log|logger -t user-data -s 2>/dev/console) 2>&1
echo "Received a termination notification on $d"
echo "Launching termination commands"
# stopping pm2 process (ui & Gekkoga)
su ec2-user -c "pm2 stop 1 2"
# archival of the results in a timestamped dir
su ec2-user -c "cd /home/ec2-user && cp -R gekko/gekkoga/results AWS/results/${d}_results"
# create the same timestamped dir on our reference server @home
ssh <YOUR_C&C_SERVER> "mkdir /home/gekko/AWS/results/${d}_results"
# upload the results on our reference server @home in two different places
scp -r /home/ec2-user/AWS/results/${d}_results/* <YOUR_C&C_SERVER>:/home/gekko/AWS/results/${d}_results
scp -r /home/ec2-user/AWS/results/${d}_results/* <YOUR_C&C_SERVER>:/home/gekko/gekko/gekkoga/results
# archive the shutdown logs on our reference server
scp -r /home/ec2-user/AWS/logs/${d}_shutdown.log <YOUR_C&C_SERVER>:/home/gekko/AWS/logs
echo "Done."
echo "===== End of Gekko Termination script ====="
break
fi
sleep 5
# doneNous l’exécutons manuellement et vérifions le journal de sortie dans $HOME/AWS/logs :

Nous vérifions maintenant sur notre serveur de référence @home si les résultats ont été téléchargés par la machine virtuelle EC2.

C’est parfait !
N’oubliez pas d’annuler les modifications que vous avez apportées précédemment dans rc.termination.handling pour tout tester : la boucle doit être activée et la vérification curl de toute erreur 404 doit être désactivée (exactement comme dans le premier exemple de script ci-dessus).
Et vous devez maintenant créer une nouvelle référence AMI basée sur cette machine virtuelle ! À partir de maintenant, toutes les demandes que vous effectuerez pour créer une nouvelle instance devront utiliser ce nouvel identifiant de référence AMI.
Étape 3 : vérification du prix des instances ponctuelles
Nous devons d’abord savoir quel type de VM nous voulons, puis nous devons vérifier les tendances des prix spot pour décider d’un prix.
Pour mon premier test, je vais choisir un c5.2xlarge, qui intègre 8 vCPU et 16 Go de mémoire. Cela devrait suffire pour lancer Gekkoga avec 7 threads simultanés.
Ensuite, nous vérifions les tendances des prix et constatons que le prix de base du marché est actuellement d’environ 0,14$. Ce sera notre prix de base dans notre demande, car nous voulons simplement tester pour l’instant.
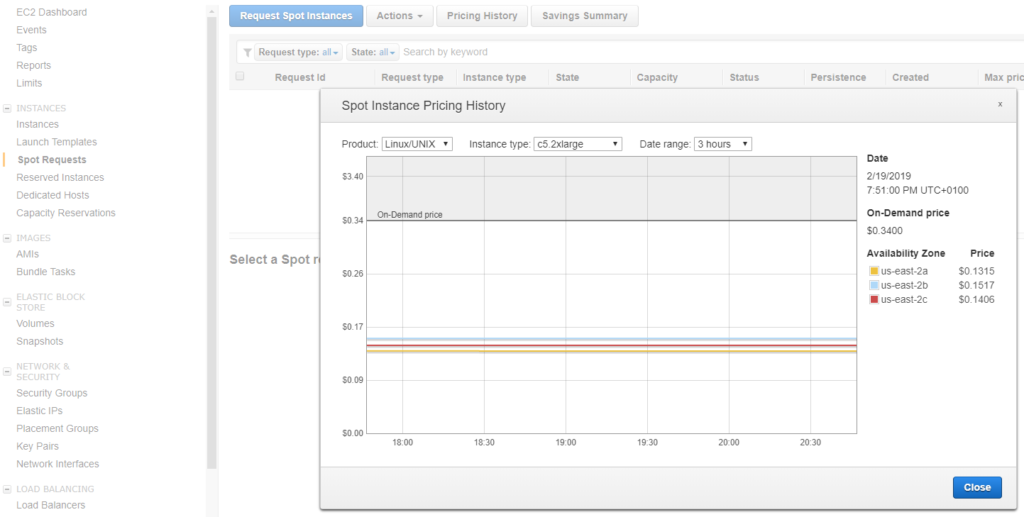
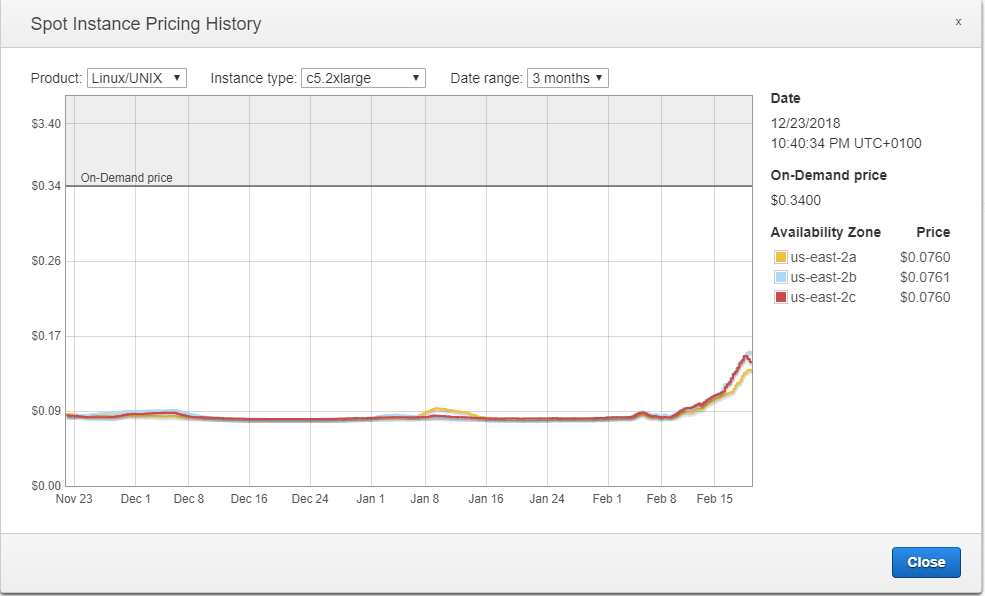
Il est également intéressant d’examiner l’évolution globale des prix sur plusieurs mois, et nous pouvons constater qu’ils ont en fait beaucoup augmenté. Nous pourrions peut-être obtenir des instances plus puissantes pour le même prix.
Vérifions le prix des machines c5.4xlarge :
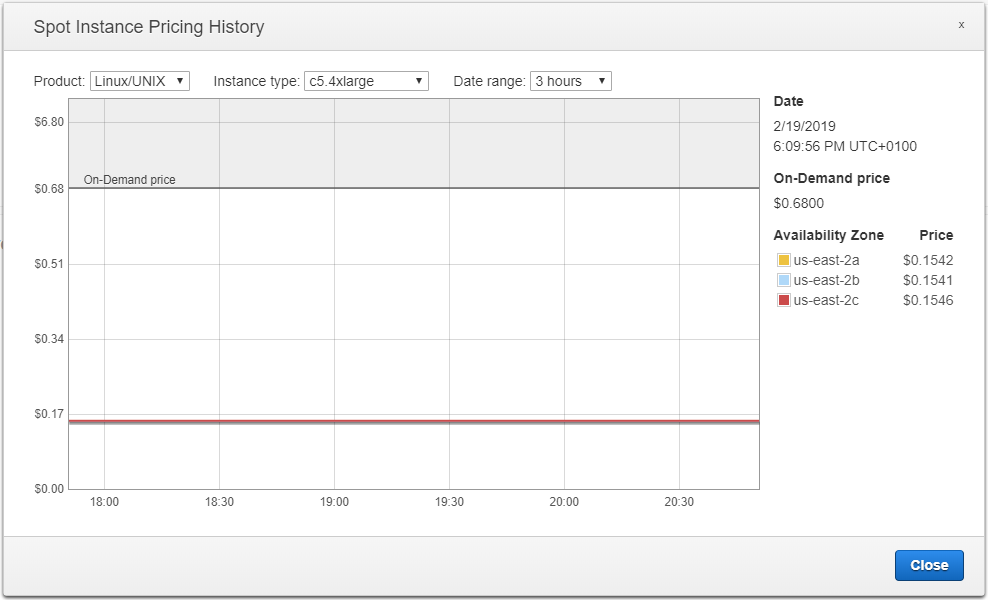
Conclusion : au moment où j’écris cette partie de l’article, pour 0,01$ de plus, nous pouvons avoir un c5.4xlarge avec 16 vCPU et 32 Go de RAM au lieu d’un c5.2xlarge avec 8 vCPU et 16 Go de RAM. Allons-y.
Étape 4 : demander une instance Spot « ponctuelle » à partir de l’interface CLI AWS
Sur notre serveur de référence @home, nous allons ensuite utiliser cette commande AWS CLI. Je l’ai intégrée dans un script shell appelé start_aws.sh, situé dans $HOME/AWS sur mon serveur C&C domestique. Pour plus de détails sur le fichier json à fournir avec la requête, consultez la documentation d’Amazon. Je décris le fichier que j’utilise ici quelques lignes plus loin.
#!/bin/bash
aws ec2 request-spot-instances --block-duration-minutes 60 --spot-price "0.34" --type "one-time" --launch-specification file://spot_specification.json --dry-runNote:
- Paramètre –dry-run : il demande à l’interface CLI de simuler la requête et d’afficher toute erreur au lieu d’essayer réellement de lancer une instance Spot.
- Cette fois-ci, pour mon premier test, j’ai utilisé une machine virtuelle « à usage unique » (paramètre –type « one-time ») avec une durée d’exécution fixe (paramètre –block-duration-minutes 60), afin de connaître précisément la durée de fonctionnement et, par conséquent, le prix est plus élevé que celui que nous avons vu ci-dessus !
- Une fois notre test réussi, nous utiliserons des machines virtuelles « spot » dont nous pourrons « demander » les prix en fonction du marché, mais dont nous ne pourrons pas anticiper la durée de fonctionnement (elles peuvent être arrêtées à tout moment par Amazon si notre prix d’appel devient inférieur au prix du marché. Sinon, vous devrez les arrêter vous-même).
Ensuite, nous créons un fichier $HOME/AWS/spot_specification.json et nous utilisons les données appropriées, en particulier notre dernière référence AMI, le type de machine, son prix demandé, la zone régionale dans laquelle l’exécuter:
{
"ImageId": "ami-0f32add64a9f98476",
"KeyName": "gekko",
"SecurityGroupIds": [ "sg-0acff95acbe908ed3" ],
"InstanceType": "c5.4xlarge",
"Placement": {
"AvailabilityZone": "us-east-2"
},
"IamInstanceProfile": {
"Arn": "arn:aws:iam::022191923083:role/Administrator"
}
}Nous essayons la ligne de commande aws cli ci-dessus pour simuler une requête…

Tout semble fonctionner correctement. Supprimons le paramètre –dry-run et lançons-le.
#!/bin/bash
aws ec2 request-spot-instances --block-duration-minutes 60 --spot-price "0.34" --type "one-time" --launch-specification file://spot_specification.json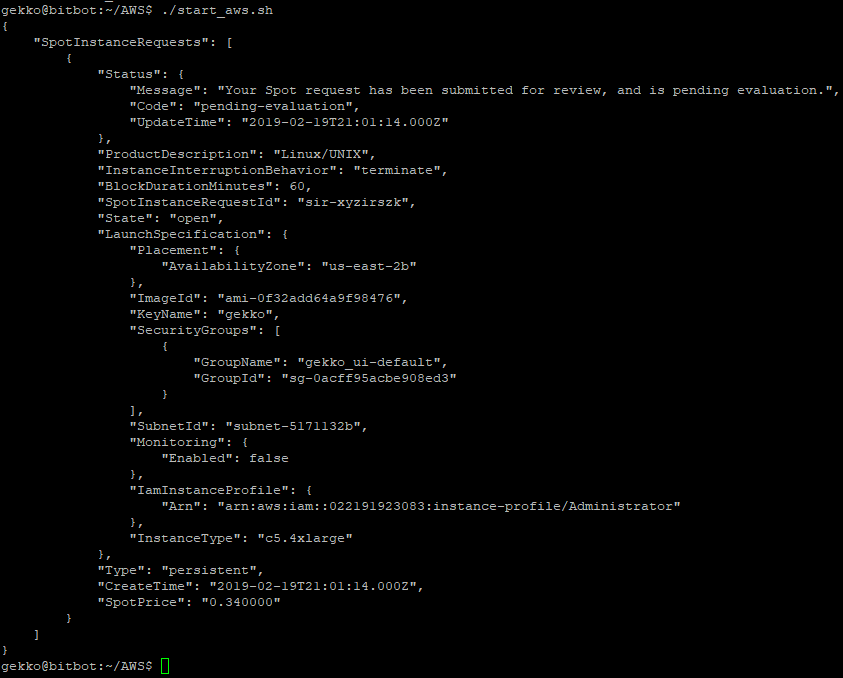
Sur la console Web EC2, nous pouvons voir notre demande, qui est déjà active, ce qui signifie que la VM a été lancée !
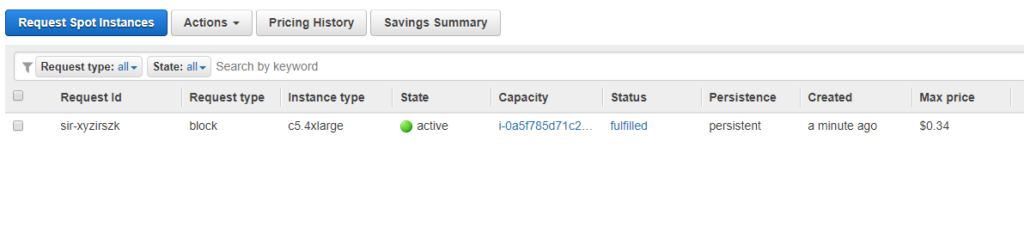
Maintenant, dans le tableau de bord principal, nous pouvons voir qu’elle est lancée, et nous obtenons son adresse IP (nous pourrions également le faire via l’interface CLI AWS) :
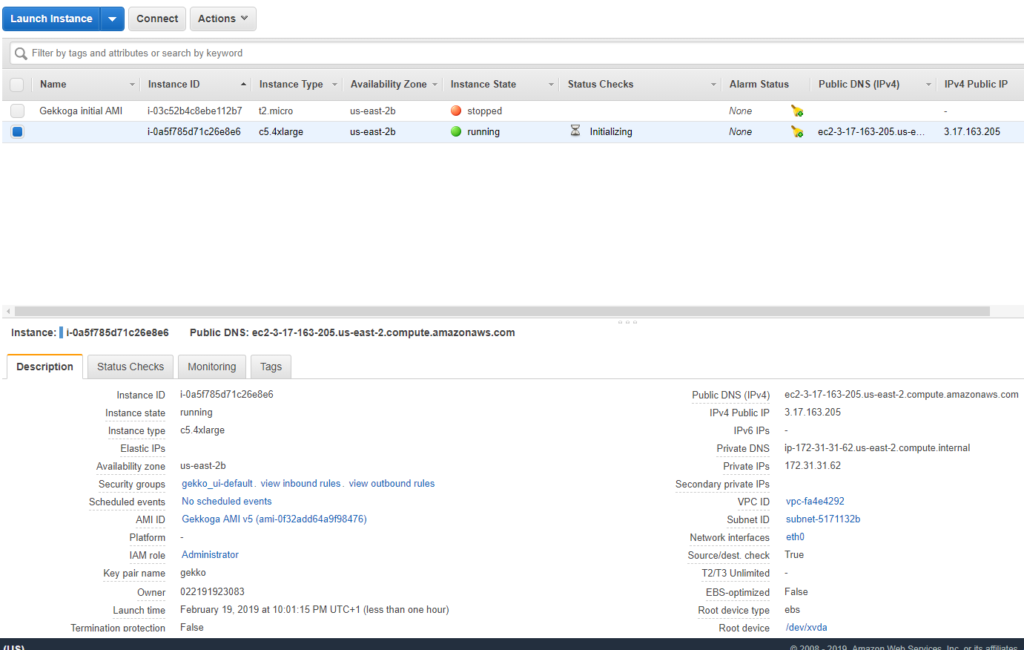
Connectons-nous via SSH et vérifions le processus en cours d’exécution :
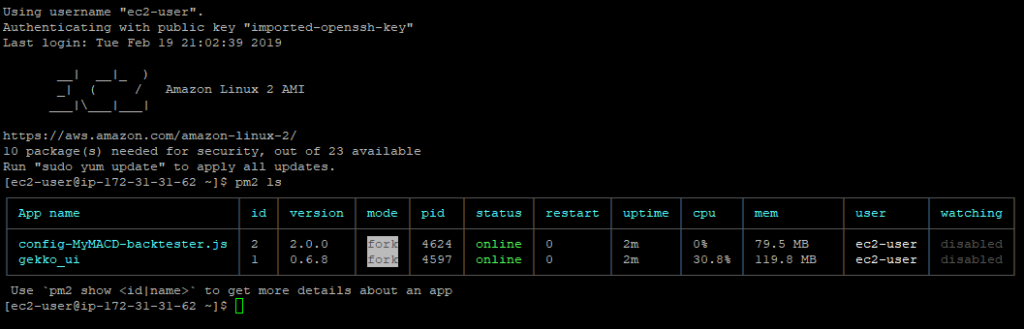
Nous pouvons voir que Gekko et GekkoGA fonctionnent tous les deux… C’est un très bon point.
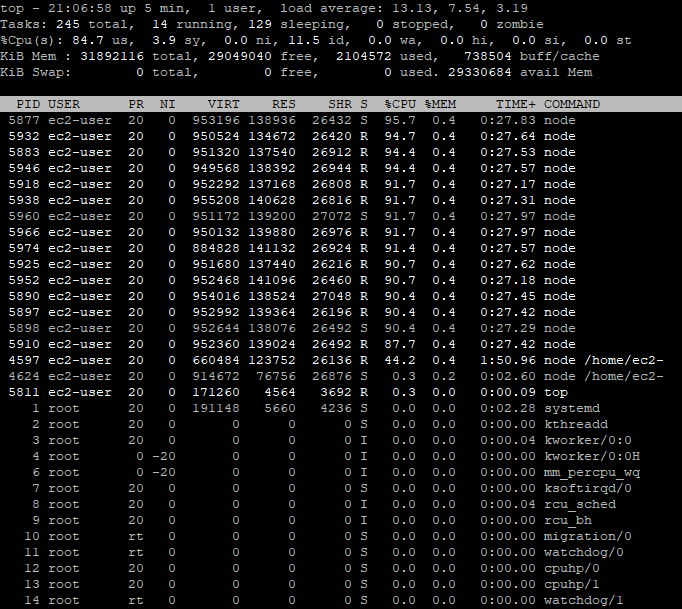
Cela semble fonctionner correctement, car nous pouvons constater que 84,7 % des processeurs sont utilisés, ce qui est assez élevé, mais normal avec GekkoGA. Et même si cela ne se voit pas, le programme fonctionne bien, car je continue de recevoir des e-mails avec les nouveaux « meilleurs résultats » trouvés par Gekkoga, puisque j’ai activé les notifications par e-mail. C’est également un bon moyen de s’assurer que vous sauvegarderez les derniers paramètres optimaux trouvés (encore une fois : il s’agit d’un backtest et cela ne signifie en aucun cas que ces paramètres sont bons pour le marché réel).
Étape 5 : première évaluation des performances
Examinons les journaux :
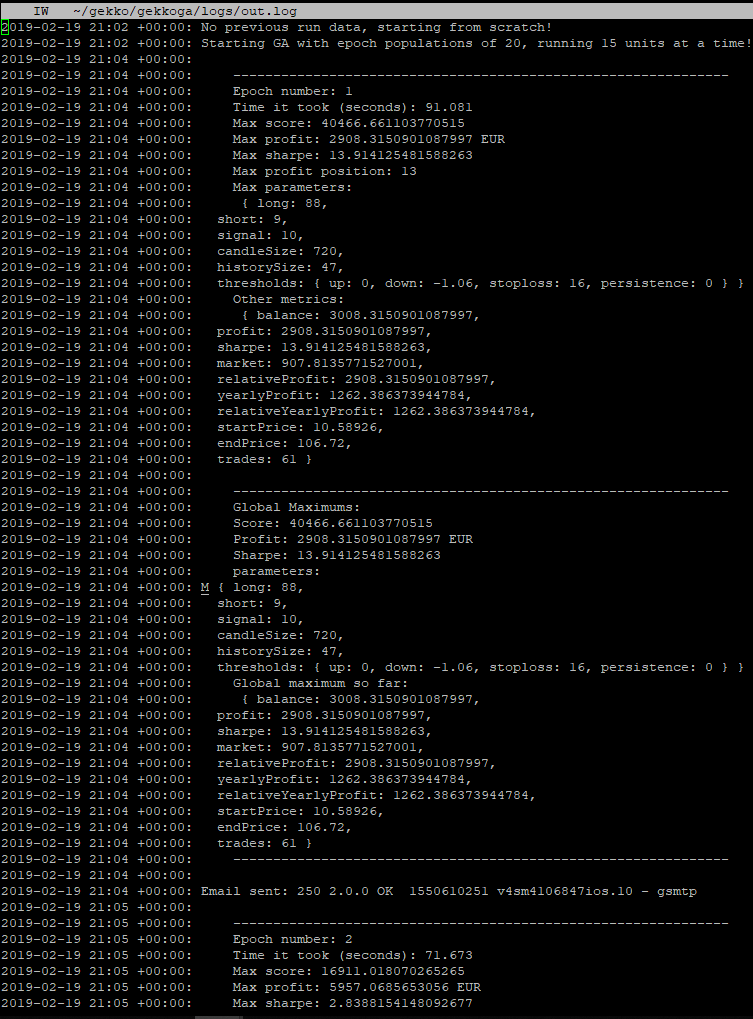
Tout fonctionne bien ! Je vais maintenant attendre une heure pour vérifier si notre processus de détection d’arrêt de VM fonctionne correctement et s’il sauvegarde le résultat sur notre serveur de référence @home.
Pendant que nous attendons… Jetons un œil dans les journaux, au temps de calcul :
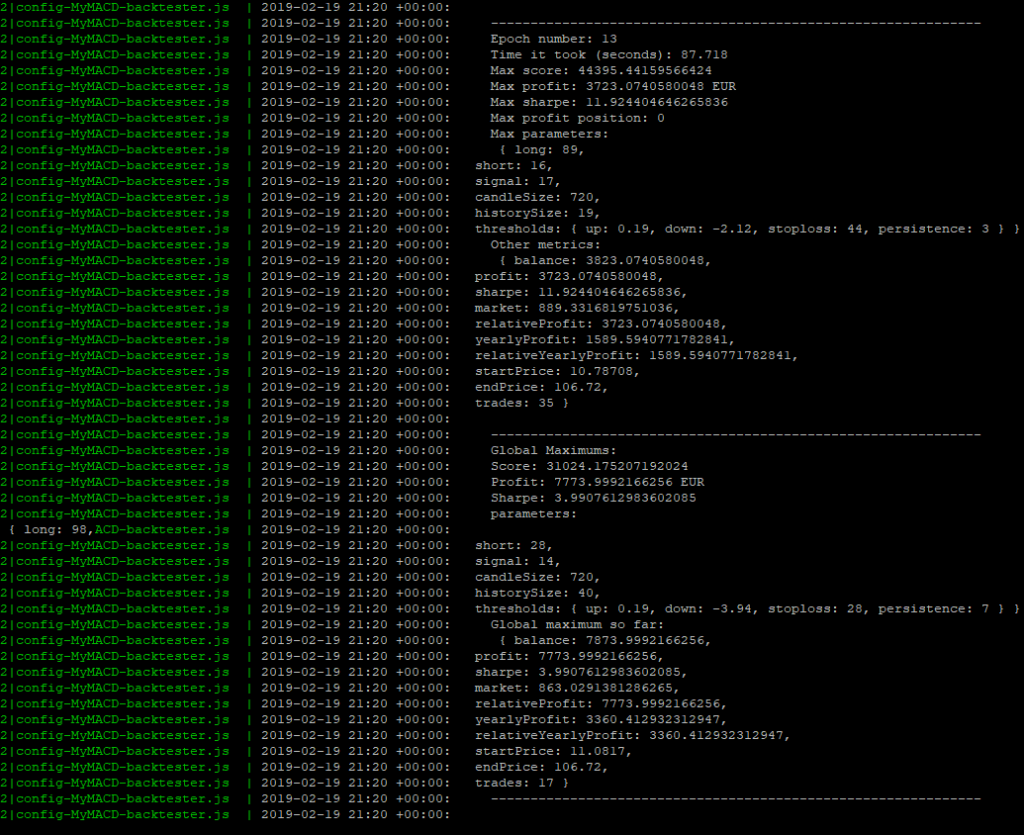
Epoch n° 13 : 87,718 s (~1,30 minute). Cela dépend des paramètres spécifiés dans notre stratégie de test et de la stratégie elle-même, mais la dernière fois que nous l’avons examinée, l’epoch n° 1 a pris 1280,646s (~21 minutes) pour s’exécuter sur notre machine virtuelle domestique, pour la même stratégie que nous avons personnalisée à titre d’exercice. Cela représente un gain de facteur 14,5… Cela s’explique facilement comme suit :
- Nous avons 16 CPU sur la VM et nous avons modifié le script de démarrage de notre GekkoGA pour utiliser N-1 = 15 CPU.
- Nous n’avons pas modifié le paramètre PopulationAmt de Gekkoga, qui est défini par défaut sur 20 (ce qui n’est pas très éloigné du nombre de CPU).
- Conclusion : GekkoGA est presque capable de lancer un backtest par CPU pour compléter une époque entière.
Une heure plus tard, j’ai réussi à revenir 2 minutes avant l’heure de fin estimée (demandée lors du lancement de la machine virtuelle, dans notre fichier json) et j’ai pu vérifier manuellement avec curl que les métadonnées de fin avaient bien été envoyées par Amazon à la machine virtuelle.
Notre script de terminaison a bien fonctionné et a téléchargé les données sur mon serveur de référence @home, à la fois dans le répertoire ~/AWS/_results et dans le répertoire gekkoga/results, afin qu’elles puissent être réutilisées lors du prochain lancement par Gekkoga.
Étape 6 : utilisation d’une instance Spot avec un prix de marché « spécifique »
Au cours des étapes précédentes, nous avons appris à demander une instance spot « ponctuelle » avec une durée fixe, ce qui signifie que nous nous sommes assurés qu’elle fonctionnerait pendant une durée spécifiée, mais à un prix plus élevé et fixe. Comme nous avons réussi à sauvegarder les données avant sa résiliation, et aussi parce que Gekkoga sait réutiliser les données précédentes qu’il trouve, nous allons désormais utiliser des instances spot moins chères, mais sans garantie qu’elles fonctionneront longtemps.
Modifions notre requête AWS CLI… Et soyons un peu fous, nous allons tester un c5.18xlarge (72 CPU, 144 Go de RAM) au prix du marché de 0,73 $ par heure. Vous remarquez les différences ? Plus de paramètres –block-duration-minutes 60 ou –type « one-time ».
#!/bin/bash
aws ec2 request-spot-instances --spot-price "0.73" --launch-specification file://spot_specification.json{
"ImageId": "ami-0f32add64a9f98476",
"KeyName": "gekko",
"SecurityGroupIds": [ "sg-0acff95acbe908ed3" ],
"InstanceType": "c5.18xlarge",
"Placement": {
"AvailabilityZone": "us-east-2b"
},
"IamInstanceProfile": {
"Arn": "arn:aws:iam::022191923083:instance-profile/Administrator"
}
}Amazon l’a lancé presque immédiatement. Connectons-nous via SSH et vérifions le nombre de processus lancés.
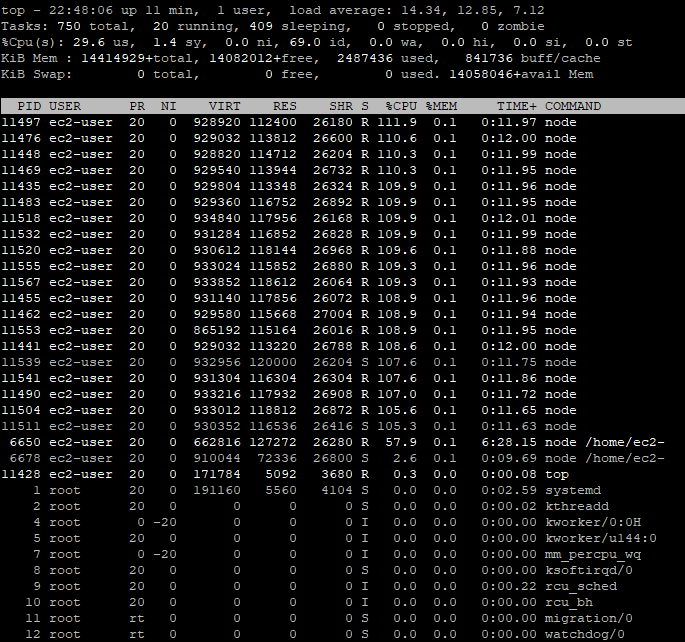
Donc… C’est assez intéressant, car parallelqueries dans gekkoga/config/config-MyMACD-backtester.js est bien réglé sur 71, MAIS il semble que le nombre maximal de processus de nœuds lancés soit limité à 23. Cela signifie qu’il n’est pas nécessaire de lancer une VM à 72 CPU, avec les paramètres réels pour la stratégie et GekkoGA. Un CPU à 16 ou 32 cœurs devrait suffire pour l’instant.
L’explication est que le paramètre populationAmt dans le fichier de configuration de GekkoGA limite le nombre de threads lancés. En le réglant sur 70, toujours avec un parallelqueries à 71, le nombre de threads augmentera et se stabilisera autour de 70, mais avec certaines périodes descendant jusqu’à 15 threads. Il serait intéressant de le représenter graphiquement et de l’étudier, mais cela fera l’objet d’un prochain article. Il existe peut-être également un goulot d’étranglement au niveau de l’interface utilisateur/API de Gekko, qui doit gérer un grand nombre de connexions provenant de tous les threads de backtesting de Gekkoga.
// Population size, better reduce this for larger data
populationAmt: 20,
// How many completely new units will be added to the population (populationAmt * variation must be a whole number!!)
variation: 0.5,
// How many components maximum to mutate at once
mutateElements: 7,Maintenant, je vais devoir commencer à lire un peu plus de documentation sur ce sujet pour trouver un bon réglage… Quoi qu’il en soit, j’utilise actuellement 140 pour populationAmt et je constate encore des baisses jusqu’à 15 threads simultanés pour nodejs.
Étape 7 : Évolution des « bénéfices estimés » sur le marché passé
Après 12 heures sans interruption (soit un coût total de 0,73 $ * 12 = 8,76 $), voici tous les e-mails que j’ai reçus pour ce premier test avec notre stratégie MyMACD personnalisée précédemment.

Comme vous pouvez le constater, avec cette stratégie, les profits sont bien meilleurs avec des bougies longues et des signaux longs. Encore une fois, cela doit être vérifié sur des ensembles de données plus petits, en particulier sur les marchés « stagnants » ou haussiers comme ceux que nous connaissons actuellement. Cette configuration et l’automatisation des tests ne vous garantissent en aucun cas de gagner de l’argent. Mais il s’agit sans aucun doute d’un nouvel outil efficace pour tester de manière intensive de nouvelles stratégies.
Remarque concernant l’utilisation de la mémoire
J’ai essayé plusieurs types de machines, j’utilise actuellement une c4.8xlarge qui dispose toujours de bons processeurs, mais d’une mémoire RAM inférieure à celle de la famille c5. Et j’ai commencé à tester une autre stratégie personnalisée. J’ai rencontré quelques plantages.
- Au départ, je pensais que cela était dû au plafonnement de l’utilisation du processeur à 100 % lorsque j’augmentais le nombre de requêtes parallèles et la valeur de populationAmt. J’ai dû annuler mes demandes de spots pour arrêter les machines virtuelles.
- À l’aide de la console EC2, j’ai vérifié les journaux de la console et j’ai pu clairement voir certaines erreurs OOM (Out of Memory) juste avant le plantage.
Ce que j’ai fait :
- Je suis allé dans le code de ma stratégie et j’ai essayé de simplifier tout ce que je pouvais, en :
- Utilisant des déclarations « let » à la place de « var » (pour réduire la portée de certaines variables),
- Supprimant une ou deux variables que je pourrais traiter différemment,
- Commentant toutes les conditions affichant des journaux, car j’aime avoir des journaux dans ma console lorsque Gekko effectue des transactions en direct. Mais pour les backtests, évitez cela : pas de journal du tout, et éliminez toutes les conditions que vous pouvez.
- J’ai également réduit le paramètre max_old_space_size à 4096 dans gekko/gekkoga/start_gekkoga.sh.
- Cela a un impact direct sur le ramasse-miettes (garbage collector – GC) de Node.
- Cela permettra au GC de collecter les données inutilisées deux fois plus souvent qu’avec le 8096 que j’avais configuré précédemment.
Depuis ces deux changements, j’exécute une nouvelle session intensive GekkoGA sur un c4.8xlarge depuis quelques heures, en utilisant 34 requêtes parallèles contre 36 vCPU. Les CPU sont occupés en permanence à 85 %, ce qui me semble satisfaisant.
Étape 8 : améliorations
Notification par e-mail au démarrage ou à l’arrêt de la machine virtuelle
Je souhaitais simplement être averti par e-mail lorsqu’une demande d’instance Spot était satisfaite. J’utilise principalement des comptes Gmail, donc la solution la plus simple que j’ai trouvée consiste à utiliser ssmtp, comme décrit ici :
sudo yum install ssmtpModifiez ensuite le fichier /etc/ssmtp/ssmtp.conf (utilisez sudo) et utilisez ces paramètres (j’ai supprimé tous les commentaires du fichier d’origine et en ai ajouté quelques-uns pour expliquer leur fonction). Vous devrez l’adapter à votre propre utilisation. Veuillez noter que Google/Gmail n’autorisera bientôt plus l’utilisation de mots de passe spécifiques à certaines applications…
# source address to be used by default in From: field
root=xxxxxxxxxxxxxxxxxx@gmail.com
# gmail server/port
mailhub=smtp.gmail.com:465
# Allows users to set their own From: address (needed to use our root address above)
FromLineOverride=YES
# Standard collection of roots CAs
TLS_CA_File=/etc/pki/tls/certs/ca-bundle.crt
# Login for your source address at gmail
AuthUser=xxxxxxxxxxxxx@gmail.com
# password for your source address at gmail (Use applications password !! Not your main one)
AuthPass=xxxxxxxxxxxxx
# Use a secure SSL/TLS connexion
UseTLS=YESPour le tester :
printf "Subject: TestnnTesting...1...2...3" | ssmtp yourDestEmail@gmail.comVous devriez recevoir l’e-mail quelques secondes plus tard. Modifions maintenant le fichier /etc/rc.local afin qu’il nous envoie un e-mail contenant quelques informations lorsque la VM démarre. J’ajoute simplement le code ci-dessous à la fin de mon fichier rc.local (avant exit 0).
echo "Sending a notification email to announce our startup ..."
TYPE=$(curl http://169.254.169.254/latest/meta-data/instance-type)
IP=$(curl http://169.254.169.254/latest/meta-data/public-ipv4)
HOSTNAME=$(curl http://169.254.169.254/latest/meta-data/public-hostname)
STRAT=$(cat /home/ec2-user/gekko/gekkoga/start_gekkoga.sh | grep TOLAUNCH= | cut -d "=" -f 2 | cut -d '"' -f 2)
NBCPU=$(getconf _NPROCESSORS_ONLN)
QUERIES=$(cat /home/ec2-user/gekko/gekkoga/config/${STRAT} | grep parallelqueries: | cut -d ":" -f 2 | cut -d "," -f 1 | cut -d " " -f 2)
printf "Subject: EC2 Instance started (${TYPE})!nnIP: ${IP}nHOSTNAME: ${HOSTNAME}nSTRAT: ${STRAT}nUsing ${QUERIES} parallelqueries vs ${NBCPU} vCPUsnType: ${TYPE}n" | ssmtp yourDestEmail@gmail.com
echo "Done."
echo "===== End of Gekko Packaging Retrieval ====="Ce que fait ce script :
- Affiche dans les journaux un message indiquant qu’un e-mail de notification est en cours d’envoi.
- Récupère divers détails spécifiques à l’instance EC2 :
- TYPE : type d’instance (par exemple, t2.micro)
- IP : adresse IP publique
- HOSTNAME : nom d’hôte public
- STRAT : nom de la stratégie lancée (extrait de
start_gekkoga.sh) - NBCPU : nombre de cœurs de processeur disponibles sur la machine virtuelle
- QUERIES : nombre de requêtes parallèles configurées pour la stratégie dans le fichier de configuration de Gekkoga.
- Rédige un e-mail en utilisant ces informations dans l’objet/le corps du message, puis l’envoie à l’adresse e-mail souhaitée à l’aide de ssmtp.
- Affiche un message de confirmation.
Pour l’adapter :
- Remplacez
yourDestEmail@gmail.compar l’adresse e-mail de destination réelle. - Assurez-vous que les chemins d’accès et les variables correspondent à votre configuration réelle.
Et, en cas de résiliation de la VM initiée par Amazon, je ferai la même chose dans /etc/rc.termination.handling (là encore, je me contenterai d’ajouter le code ci-dessous à la fin du script, avant les lignes break/fi/sleep 5/#done.
echo "Sending a notification email to announce our termination ..."
TYPE=$(curl http://169.254.169.254/latest/meta-data/instance-type)
IP=$(curl http://169.254.169.254/latest/meta-data/public-ipv4)
HOSTNAME=$(curl http://169.254.169.254/latest/meta-data/public-hostname)
STRAT=$(cat /home/ec2-user/gekko/gekkoga/start_gekkoga.sh | grep TOLAUNCH= | cut -d "=" -f 2 | cut -d '"' -f 2)
NBCPU=$(getconf _NPROCESSORS_ONLN)
QUERIES=$(cat /home/ec2-user/gekko/gekkoga/config/${STRAT} | grep parallelqueries: | cut -d ":" -f 2 | cut -d "," -f 1 | cut -d " " -f 2)
printf "Subject: EC2 Instance will STOP (${TYPE})!nnIP: ${IP}nHOSTNAME: ${HOSTNAME}nSTRAT: ${STRAT}nUsing ${QUERIES} parallelqueries vs ${NBCPU} vCPUsnType: ${TYPE}n" | ssmtp yourDestEmail@gmail.com
echo "Done."
echo "===== End of Gekko Termination script ====="
break
fi
sleep 5
#done
Ici encore, pour adapter, remplacez yourDestEmail@gmail.com par l’adresse e-mail de notification réelle et vérifiez les chemins/variables.
Voici un exemple de ce que vous recevrez si vous utilisez les exemples ci-dessus. Notez que j’ai fait une faute de frappe dans mon script, le type de machine à la fin de l’e-mail n’est pas bien formaté ci-dessous, mais je l’ai corrigé dans le code ci-dessus lorsque je m’en suis aperçu :
Vérification en direct des nouveaux résultats et synchronisation automatique avec le serveur domestique C&C
J’ai ajouté un utilitaire de surveillance des fichiers pour détecter « en direct » tout changement dans le répertoire des résultats de Gekkoga, afin de le télécharger immédiatement sur mon serveur de référence @home. J’ai dû faire cela parce que j’ai remarqué que lorsque vous demandez à Amazon de mettre fin à une demande Spot associée à une machine virtuelle en cours d’exécution, cela tue presque immédiatement la machine virtuelle, sans annonce préalable. Ainsi, les résultats n’étaient pas toujours synchronisés sur mon serveur C&C domestique.
Quoi qu’il en soit, grâce aux notifications par e-mail, j’avais dans ma boîte mail tous les détails de toutes les configurations stratégiques « élues » par l’algorithme génétique.
Script start_aws.sh avancé pour le serveur domestique C&C
J’ai développé un script de lancement de machine AWS beaucoup plus avancé que celui utilisé ci-dessus. Ce script Bash automatise à la fois la consultation des prix Spot et le lancement de nouvelles instances AWS Spot pour les charges de travail intensives de Gekkoga.
Veuillez remplacer $HOME/AWS/start_aws.sh sur votre serveur domestique C&C par celui-ci :
#!/bin/bash
TYPE=$1
PRICE=$2
REGION=$3
STRAT=`grep "TOLAUNCH=" $HOME/gekko/gekkoga/start_gekkoga.sh | cut -d """ -f 2`
ASSET=`grep "ASSETTOUSE=" $HOME/gekko/gekkoga/start_gekkoga.sh | cut -d """ -f 2`
if [ "$#" -eq 1 ]; then
echo "Checking ${TYPE} prices ..."
aws ec2 describe-spot-price-history --start-time=$(date +%s) --product-descriptions="Linux/UNIX" --query 'SpotPriceHistory[*].{az:AvailabilityZone, price:SpotPrice}' --instance-types ${TYPE}
else
if [ "$#" -eq 3 ]; then
echo "Requesting a ${TYPE} Spot instance at ${PRICE} ..."
InstanceType=" "InstanceType": "${TYPE}","
echo ${InstanceType}
sed -i "/InstanceType/c ${InstanceType}" spot_specification.json
AvailabilityZone=" "AvailabilityZone": "${REGION}""
echo ${AvailabilityZone}
sed -i "/AvailabilityZone/c ${AvailabilityZone}" spot_specification.json
Name="${STRAT} - ${ASSET}"
echo ${Name}
spotInstanceRequestId=`aws ec2 request-spot-instances --spot-price "${PRICE}" --launch-specification file://spot_specification.json --query 'SpotInstanceRequests[0].[SpotInstanceRequestId]' --output text`
echo "Waiting a bit before trying to grab InstanceId from our request ${spotInstanceRequestId} ..."
sleep 5
while [ -z `aws ec2 describe-spot-instance-requests --spot-instance-request-ids ${spotInstanceRequestId} |grep "InstanceId" | cut -d """ -f 4` ]; do
echo "Instance still not launched, waiting 5s more ..."
echo "Status is: "
aws ec2 describe-spot-instance-requests --spot-instance-request-ids ${spotInstanceRequestId} |grep "Message" | cut -d """ -f 4
sleep 5
done
InstanceId=`aws ec2 describe-spot-instance-requests --spot-instance-request-ids ${spotInstanceRequestId} |grep "InstanceId" | cut -d """ -f 4`
echo "Instance created ! InstanceId: ${InstanceId}"
InstanceIP=`aws ec2 describe-instances --instance-ids ${InstanceId} --query 'Reservations[*].Instances[*].PublicIpAddress' --output text`
echo "Public IP: ${InstanceIP}"
aws ec2 create-tags --resources ${InstanceId} --tags "Key=Name,Value=$Name"
echo "Instance ${InstanceId} named: ${Name}"
else
echo "Pass 1 OR 3 parameters:"
echo "targ1: EC2 instance type (to request its Spot price)"
echo " ex1: ./start_aws.sh c5.4xlarge"
echo " ex2: ./start_aws.sh c5.9xlarge"
echo " ex3: ./start_aws.sh c5.18xlarge"
echo "targ2: requested price (to launch an instance)"
echo "targ3: requested region(to launch an instance)"
echo " ex1: ./start_aws.sh c5.4xlarge 0.162 us-east-2a"
echo " ex2: ./start_aws.sh c5.9xlarge 0.325 us-east-2b"
echo " ex3: ./start_aws.sh c5.18xlarge 0.325 us-east-2b"
fi
fiVoici un aperçu de ses principales fonctionnalités :
1. Recherche flexible du prix au comptant ou lancement d’instance
- Si vous appelez le script sans paramètres, il affichera une aide.
- Si vous appelez le script avec un seul paramètre (type d’instance) :
- Il interroge et affiche le prix Spot actuel pour le type d’instance EC2 spécifié dans toutes les zones de disponibilité.
- Utile pour vérifier rapidement le prix Spot nécessaire avant de lancer une instance, et également pour connaître les noms des zones (obligatoire pour demander une VM).
- Si vous appelez le script avec trois paramètres (type d’instance, prix souhaité et zone de disponibilité) :
- Il modifie automatiquement votre fichier
spot_specification.jsonafin de définir le type d’instance et la zone de disponibilité adaptés à votre demande. - Il envoie ensuite une demande d’instance ponctuelle au prix spécifié à l’aide de votre fichier de configuration de lancement prédéfini.
- Il modifie automatiquement votre fichier
2. Suivi et balisage automatisés des instances
- Une fois la demande d’instance Spot envoyée, le script interroge AWS toutes les 5 secondes jusqu’à ce que l’instance demandée soit effectivement lancée et qu’un
InstanceIdsoit attribué. - Il récupère l’adresse IP publique de la nouvelle instance dès qu’elle est disponible.
- L’instance est alors automatiquement nommée d’après votre stratégie et votre ressource actuellement définies (extraites directement de
start_gekkoga.sh), ce qui facilite le suivi et l’identification des instances lancées dans la console AWS.
Principaux avantages
- Pas d’édition manuelle : tous les paramètres de lancement sont définis à la volée, plus besoin de bidouiller le JSON.
- Visibilité immédiate : consultez l’état de l’instance et l’adresse IP publique dès le lancement.
- Cohérence : le nom de l’instance reflète la stratégie et les ressources utilisées, ce qui facilite les exécutions par lots et le suivi des coûts.
- Polyvalence : utilisez le même script pour surveiller les tendances des prix Spot et automatiser le lancement d’instances.
Exemple d’utilisation
- Vérifier le prix Spot actuel :
./start_aws.sh c5.4xlarge - Demander une nouvelle instance Spot :
./start_aws.sh c5.9xlarge 0.32 us-east-2a
Script permettant d’annuler les demandes d’instances
Vous ne pouvez pas modifier les paramètres de votre demande d’instance Spot, y compris votre prix maximum, après avoir soumis la demande. Mais vous pouvez les annuler si leur statut est ouvert ou actif. Voici un exemple de base de script qui répertorie vos demandes et les annule.
#!/bin/bash
#get instances requests (2 different ways)
InstanceID=$(aws ec2 describe-spot-instance-requests --query SpotInstanceRequests[*].{ID:InstanceId} | grep ID | cut -d """ -f 4)
SpotInstanceRequestId=$(aws ec2 describe-spot-instance-requests --query SpotInstanceRequests[*].{ID:SpotInstanceRequestId} | grep ID | cut -d """
#display both lists of requests
echo ${InstanceID}
echo ${SpotInstanceRequestId}
#todo: ajout connexion ssh ec2 et synchro reps logs
#cancel requests
aws ec2 cancel-spot-instance-requests --spot-instance-request-ids ${SpotInstanceRequestId}
Choses à retenir
- Amazon EC2 lancera votre instance Spot lorsque le prix maximum que vous avez spécifié dans votre demande dépassera le prix Spot réel et que la capacité sera disponible dans la région que vous avez demandée. L’instance Spot fonctionnera jusqu’à ce qu’elle soit interrompue par Amazon ou que vous la terminiez vous-même. Si votre prix maximum reste supérieur ou égal au prix Spot, votre instance Spot continuera à fonctionner… pendant longtemps, en fonction de la demande. Si vous l’oubliez, cela pourrait vous coûter cher !
- Comme expliqué dans la documentation Amazon, si une demande d’instance Spot que vous avez effectuée est active et associée à une instance Spot en cours d’exécution, l’annulation de la demande ne met pas fin à l’instance. Pour plus d’informations sur la résiliation d’une instance Spot, consultez l’aide Résilier une instance Spot.
- Il n’y a PAS PLUS DE GARANTIE que vous gagnerez de l’argent maintenant que vous avez automatisé des tests plus rapides sur des machines plus puissantes. EN REVANCHE CE QUI EST SÛR ET QUE JE PEUX VOUS GARANTIR, C’EST QUE CELA VOUS COÛTERA PLUS CHER EN TESTs.
Réflexions et recherches sur des paramètres spécifiques aux algorithmes génétiques
Le réglage standard de GekkoGA à 7 mutations semble beaucoup trop élevé (à mon avis) pour une stratégie de base qui ne comporte pas beaucoup de paramètres dynamiques à tester (8 avec notre exemple MyMACD dans ces guides) et une population limitée à 20. Je pense que certains paramètres muteront trop fréquemment. Les mutations sont une bonne chose, mais je suis d’avis que nous avons besoin de stabilité dans le pool génétique pour favoriser le croisement de bons gènes, plutôt que d’introduire des mutations quasi systématiques. Pour l’instant, mais je dois lire davantage de littérature à ce sujet et effectuer plus de tests, j’ai le sentiment que si nous voulons changer autant de gènes, nous devons également augmenter le nombre d’individus dans la population.
Le dilemme de la boucle sans fin de réglage
Je n’ai pas de configuration idéale pour GekkoGA. Il faut faire plus de tests, c’est un nouveau défi. En réalité, je crains le dilemme de la « boucle de réglage » avec les algorithmes génétiques ou évolutionnaires : l’utilisation d’un algorithme génétique pour régler les paramètres d’un autre algorithme est désormais courante dans l’optimisation et l’apprentissage automatique. Mais cela soulève rapidement une méta-question : comment choisir les bons paramètres pour l’Algorithme Génétique lui-même ? Ne faisons-nous pas que déplacer le problème à un niveau supérieur ?
Pourquoi est-ce un défi ?
Un mauvais réglage des paramètres conduit soit à une convergence précoce (optimum local), soit à des calculs inutilement longs pour des gains minimes (inefficacité). La qualité des résultats de l’algorithme génétique dépend fortement de ses propres paramètres : taille de la population, taux de mutation, taux de croisement, nombre de générations, etc. (voir ci-dessous). Il n’existe pas de solution universelle : les paramètres optimaux dépendent du problème, du codage et même du « caractère aléatoire », et parfois du budget (temps/puissance de calcul) dont vous disposez.
Paramètres génériques GA et GekkoGA
1. Taille de la population
- Problème : une population trop petite peut converger trop rapidement (perte de diversité et blocage dans des optimums locaux).
Une population trop grande augmente le temps de calcul sans nécessairement améliorer les résultats. - Dans GekkoGA, il s’agit du paramètre
populationAmt. Il s’agit simplement de la taille de la population pour chaque génération de l’algorithme génétique.- À chaque « epoch », ce nombre d’individus (les solutions candidates) sera pris en compte.
- Approche pratique que je suggère : commencez avec 30 à 100 individus, puis ajustez en fonction de la complexité de votre problème. Testez toujours plusieurs valeurs.
2. Taux de mutation
- Problème : S’il est trop faible, l’algorithme n’explorera pas suffisamment l’espace de solutions ; s’il est trop élevée, l’AG se transforme en recherche aléatoire.
- Dans GekkoGA, cela définit le nombre maximal de « gènes » (paramètres de la stratégie) pouvant être mutés pour les individus « non générés aléatoirement » lors d’une mutation.
- Exemple : pour un individu avec 10 paramètres/gènes, si
mutateElements: 7, alors jusqu’à 7 paramètres peuvent être mutés en même temps, mais jamais plus, chaque fois qu’une opération de mutation d’un individu est appliquée pour obtenir une nouvelle population.
- Exemple : pour un individu avec 10 paramètres/gènes, si
- Pratique courante : utilisez un taux de mutation initial compris entre 0,5 % et 5 %. Des stratégies de mutation adaptative (augmentation de la mutation lorsque les progrès stagnent) permettent de maintenir la diversité et d’éviter de rester bloqué dans des solutions médiocres. La mutation adaptative n’est pas disponible dans GekkoGA.
3. Introduction de nouveaux gènes (maintien de la diversité)
- Problème : Si une population devient trop homogène, le croisement cesse de produire de nouvelles solutions intéressantes.
- Solution : injecter régulièrement de nouveaux individus générés aléatoirement (« immigration génétique ») ou forcer des mutations chez certains individus afin de stimuler l’innovation.
- Dans GekkoGA, le paramètre
variationindique la proportion d’individus « nouveaux » (variés aléatoirement) ajoutés à la population à chaque génération de nouvelle population. Ces nouveaux individus ne sont pas le résultat d’un croisement ou d’une mutation, mais sont générés « à partir de zéro » selon les règles de la stratégie.- Exemple avec populationAmt : 60 et variation : 0,8 : 0,8 × 60 = 48 nouveaux individus sont créés aléatoirement à chaque génération (les 12 restants sont produits par croisement/mutation des meilleurs individus de la génération précédente).
4. Nombre de générations (epochs)
- Problème : un arrêt prématuré conduit à des solutions sous-optimales ; un nombre trop élevé de générations entraîne un gaspillage de ressources informatiques.
- Meilleure pratique : utilisez un critère d’arrêt (par exemple, aucune amélioration après N générations) ou un nombre fixe de générations basé sur … votre expérience. Suivez l’évolution des résultats (fitness) pour guider votre choix.
5. Les pièges classiques
- Convergence prématurée : diversité insuffisante ; l’AG se stabilise rapidement à un optimum local.
- Surajustement : le GA « apprend » les particularités d’un ensemble de données spécifique plutôt que les modèles généraux (fréquent lorsqu’il y a trop de générations ou une population trop importante).
- Coût de calcul : la taille de la population et de l’espace de recherche peuvent augmenter de manière exponentielle les temps d’exécution.
6. Meilleures pratiques et stratégies modernes
- Testez plusieurs paramètres et utilisez des paramètres adaptatifs (tels que les taux de mutation dynamiques).
- Introduisez régulièrement de la diversité.
- Surveillez le meilleur score, le résultat moyen des epochs et la diversité génétique à chaque génération (facile à écrire … moins à faire).
- Combiner l’algorithme génétique avec d’autres approches d’optimisation (méthodes hybrides ou de recherche locale).
Comment mettre en oeuvre dans la pratique ?
- Méta-optimisation (réglage automatisé)
- Le principe consiste à utiliser une autre couche d’optimisation (même un autre AG, une optimisation bayésienne ou une recherche par grille/aléatoire) pour rechercher des paramètres AG efficaces.
- Oui : il s’agit bien d’un risque de « récursivité » (la fameuse boucle évoquée plus haut), mais dans la pratique, l’automatisation et la parallélisation permettent de le gérer pour la plupart des problèmes concrets.
- Des outils tels que Optuna, Hyperopt ou même des scripts génétiques « méta GA » existent à cette fin (parfois appelés « hyper-GA » ou « méta-GA »). Je ne les ai pas essayés.
- Valeurs par défaut théoriques et empiriques
- Des décennies de recherche et d’expérience partagée ont permis d’établir des valeurs par défaut raisonnables pour la plupart des problèmes. Par exemple :
- Taille de la population : 30 à 100 (pour de nombreux problèmes économiques/d’ingénierie)
- Mutation/croisement : mutation de 1 à 5 %, croisement de 60 à 90 %.
- Nombre de générations : dépend du problème, mais souvent jusqu’à stagnation ou valeur maximale
- De nombreuses applications pratiques se contentent de réaliser quelques expériences pour affiner ces quelques méta-paramètres de haut niveau.
- C’est la technique du « parameter sweep »: on lance juste quelques essais (runs) avec différentes valeurs pour sélectionner les plus efficaces. Contrairement à des méthodes plus avancées (Bayésiennes, évolutives), le parameter sweep est une approche systématique, basique mais fréquemment suffisante en pratique.
- Des décennies de recherche et d’expérience partagée ont permis d’établir des valeurs par défaut raisonnables pour la plupart des problèmes. Par exemple :
- GA adaptatifs et auto-ajustables
- Certains AG avancés (malheureusement pas GekkoGA) adaptent leurs paramètres pendant l’exécution, par exemple en augmentant le taux de mutation si les progrès stagnent ou en ajustant la pression de sélection en fonction de la diversité.
- Cela tente de briser la boucle « serpent se mordant la queue » en laissant l’algorithme s’ajuster à la volée.
Conclusion et lectures complémentaires
L’automatisation des backtests à grande échelle avec Gekkoga sur les instances EC2 Spot ouvre d’énormes possibilités pour l’analyse quantitative, au prix d’une ingénierie et d’un réglage minutieux des paramètres. L’infrastructure AWS Spot vous permet de tester par force brute des milliers de stratégies candidates à des vitesses auparavant inabordables, mais uniquement si vous automatisez également la gestion des arrêts et la conservation des données.
Points clés à retenir
- Les instances Spot avec beaucoup de CPU peuvent considérablement accélérer l’optimisation de votre stratégie basée sur l’algorithme génétique, à condition que vous ajustiez à la fois votre infrastructure et les paramètres de votre algorithme génétique.
- Il n’existe pas de paramètres GA universels ; la taille de la population, le taux de mutation/croisement et les mécanismes de diversité doivent tous être ajustés de manière empirique. Il s’agit là d’un domaine de recherche à part entière.
- L’automatisation des notifications, la synchronisation des résultats et le nettoyage des ressources transforment une expérience de test initialement amusante en un outil de production robuste.
Certains défis demeurent
- Le dilemme de la « boucle d’ajustement des paramètres » : optimiser les paramètres GA sans tomber dans une spirale d’ajustement sans fin.
- Facturation AWS : l’utilisation prolongée de machines surdimensionnées augmentera les coûts. Surveillez en permanence l’utilisation et automatisez le nettoyage des instances !
Bibliographie et ressources recommandées
- Paramètres, réglage et diversité des algorithmes génétiques :
- Optimisation des algorithmes génétiques pour les problèmes urgents (PDF) – Présentation académique complète du réglage des paramètres, y compris la mutation adaptative.
- Vos 8 conseils avancés pour optimiser les algorithmes génétiques – Conseils pratiques et illustrés pour une utilisation moderne des AG.
- Wikipédia : Algorithme génétique (français) – Introduction en français, axée sur la population/diversité.
- Analyse des stratégies de mutation – Meilleures pratiques pour équilibrer les taux de mutation et la population.
- Une nouvelle stratégie pour adapter la probabilité de mutation dans les AG (PDF) – Pour ceux qui souhaitent mettre en œuvre une mutation auto-adaptative.
- AWS et automatisation :
- Liens internes vers des articles de mon blog traitant de sujets avancés :
Si vous avez des commentaires, des corrections ou des expériences à partager (bonnes ou mauvaises !), n’hésitez pas à les poster ci-dessous ou à me contacter directement. L’amélioration continue est au cœur des approches évolutives et des connaissances communautaires !
En savoir plus sur SINECU.RE
Subscribe to get the latest posts sent to your email.