Nous avons essayé le backtesting de Gekkoga et avons remarqué qu’il sollicitait beaucoup le CPU. Je n’avais jamais utilisé Amazon EC2 et sa capacité à déployer rapidement des serveurs, mais j’étais curieux de le tester, car il pouvait parfaitement répondre à nos besoins : la location à la demande de serveurs à haute capacité, en utilisant la fonctionnalité « Spot instance » d’Amazon. Attention, sur EC2, seule la plus petite machine virtuelle peut être utilisée gratuitement (ou presque). Les serveurs que je souhaite utiliser en cible (prochain article) ne sont pas gratuits.
Vous souhaitez savoir comment tirer parti d’Amazon EC2 pour exécuter des backtests Gekko et Gekkoga à grande échelle sans surcharger votre processeur local ?
Ce guide vous montrera, étape par étape, comment déployer une micro-instance EC2 gratuite (ou presque gratuite), installer tous les paquets nécessaires et automatiser l’exécution des backtests de votre propre stratégie de trading. Nous allons créer une nouvelle AMI personnalisée basée sur l’AMI standard d’Amazon que nous aurons déployée, y compris les logiciels personnalisés et une partie de leur configuration. Ensuite, nous automatiserons dans un simple fichier batch la demande, la commande et l’exécution d’une nouvelle instance basée sur notre AMI personnalisée, avec lancement automatique des backtests Gakkoga et collecte de ses résultats. Ce fichier batch sera utilisé à partir de mon propre serveur gekko personnel/domestique (aussi appelé parfois plus bas serveur de référence ou « command & control » server) que j’utilise pour modifier et tester rapidement de nouvelles stratégies. Vous pourrez faire de même depuis chez vous.
À la fin, vous saurez exactement comment créer, cloner et multiplier vos propres environnements de backtesting basés sur le cloud, même si vous êtes novice en matière d’AWS ou de robots de trading algorithmiques !
Étape 1 : création d’une nouvelle machine virtuelle de test Amazon EC2 t2.micro
Tout d’abord, vous devez créer un compte AWS. Oui, vous devrez saisir les détails de votre carte de crédit. Une machine EC2 t2.micro est gratuite, la plupart des services sont aussi gratuits au début, mais certaines actions (comme l’attribution puis la libération d’une adresse IP élastique) peuvent entraîner des frais minimes. Même l’instance micro EC2 gratuite ne peut être exécutée que pendant un nombre d’heures limité par mois. C’est pourquoi nous nous en servons ici uniquement pour nous créer une Machine Virtuelle de « référence » (une AMI = Amazon Machine Image) que nous clonerons. N’oubliez donc pas d’arrêter votre instance lorsque vous ne l’utilisez pas. C’est la politique « à la demande » d’Amazon : utilisez là quand vous en avez besoin, ne payez que ce que vous consommez.
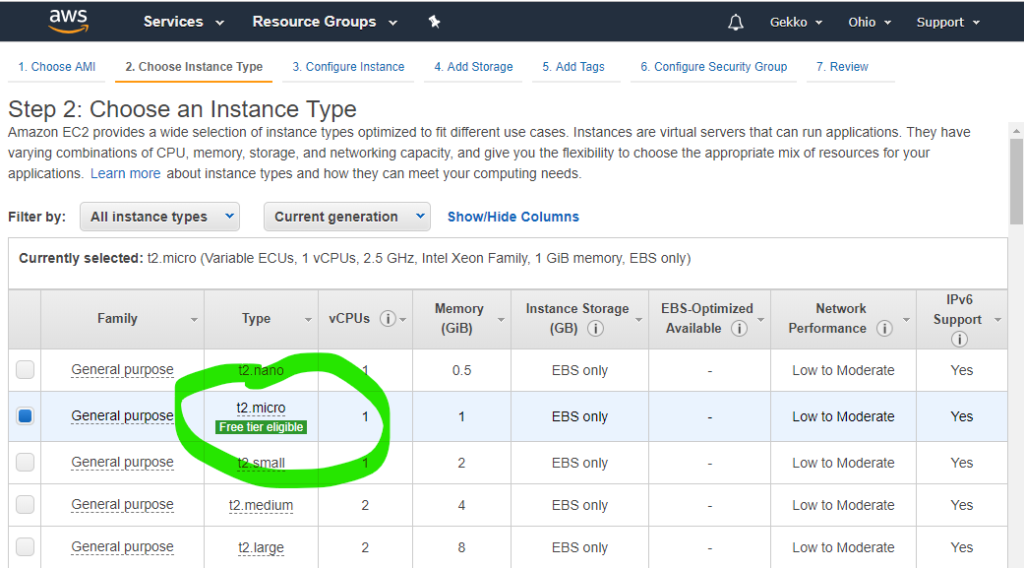
Ensuite, nous choisissons l’AMI, puis la plus petite machine virtuelle disponible, comme le permet le forfait « gratuit » d’Amazon.
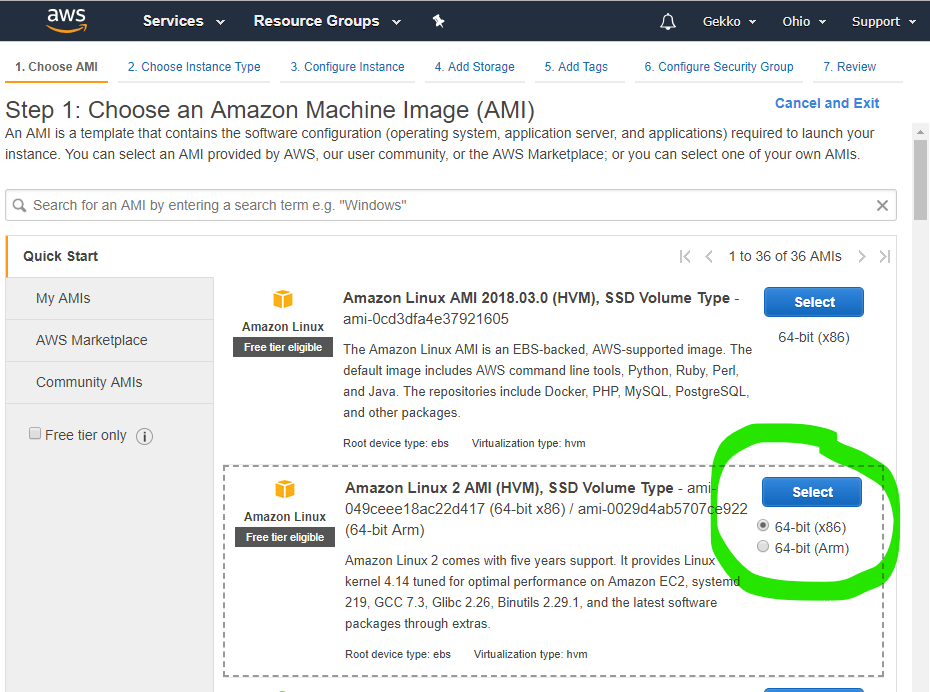
Au bas de la page, cliquez sur « Suivant : configurer les détails de l’instance ». Sur la page suivante, vous pouvez utiliser toutes les valeurs par défaut, mais vérifiez :
- Option d’achat : vous pouvez demander une instance Spot. Il s’agit de la place de marché d’Amazon où vous fixez votre prix maximum.
- Les détails avancés en bas.

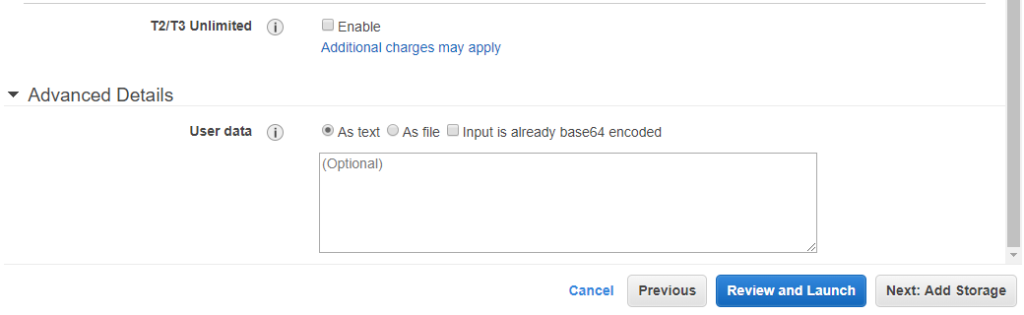
Le champ « Données utilisateur » permet d’utiliser un script shell qui sera exécuté au démarrage par la machine virtuelle. Comme la machine virtuelle peut parfois être démarrée lorsque Amazon détecte qu’elle doit l’être (par exemple, les instances Spot et atteinte du prix demandé), cette fonctionnalité très pratique permet de configurer automatiquement votre instance pour qu’elle télécharge certains éléments de configuration spécifiques au démarrage, par exemple notre stratégie Gekko et nos fichiers de configuration pour lancer automatiquement nos backtests. Nous essaierons cela plus tard (je ne l’ai pas encore essayé moi-même au moment où j’écris ces lignes, mais cela est bien documenté par Amazon).
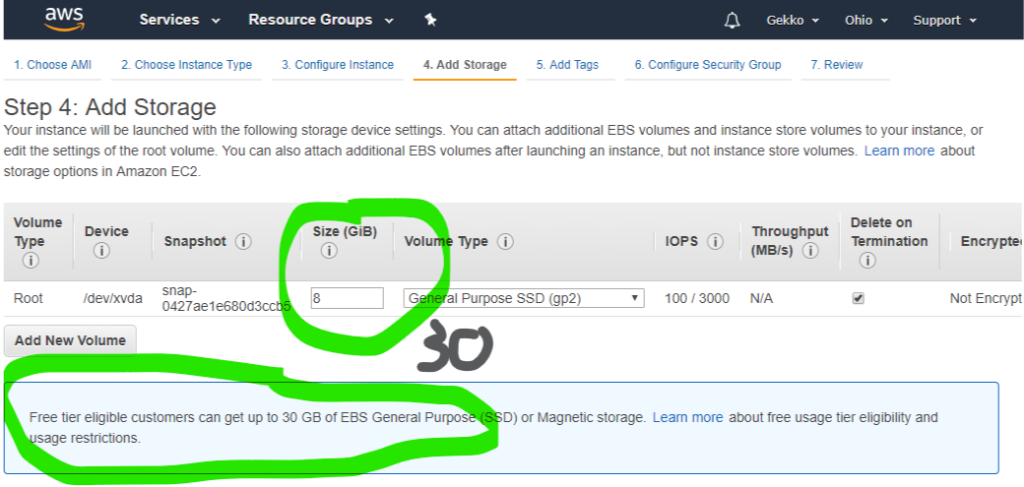
Ensuite, nous voulons configurer le stockage, car Amazon nous permet (au moment où j’écris cet article) d’utiliser 30 Go sur la machine virtuelle gratuite au lieu des 8 Go par défaut.
Ensuite, j’ajoute une balise expliquant l’objectif de cette machine virtuelle et de ce stockage (je ne sais pas encore si on s’en servira concrètement à l’avenir, mais peu importe …).
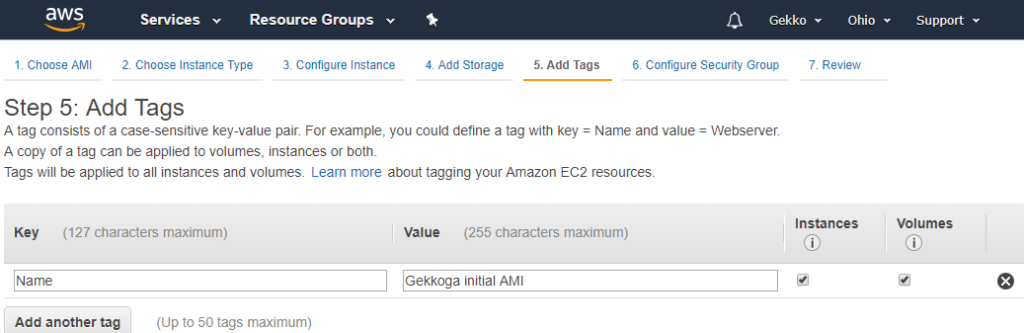
Ensuite, nous configurons un groupe de sécurité. Comme j’ai déjà un peu joué avec une autre VM, j’ai créé un groupe de sécurité personnalisé qui autorise les ports 22 (SSH), 80 (HTTP) et 443 (HTTPS). Je l’ai choisi ici, mais vous pourrez faire la même chose et mapper votre propre groupe de sécurité à votre VM.
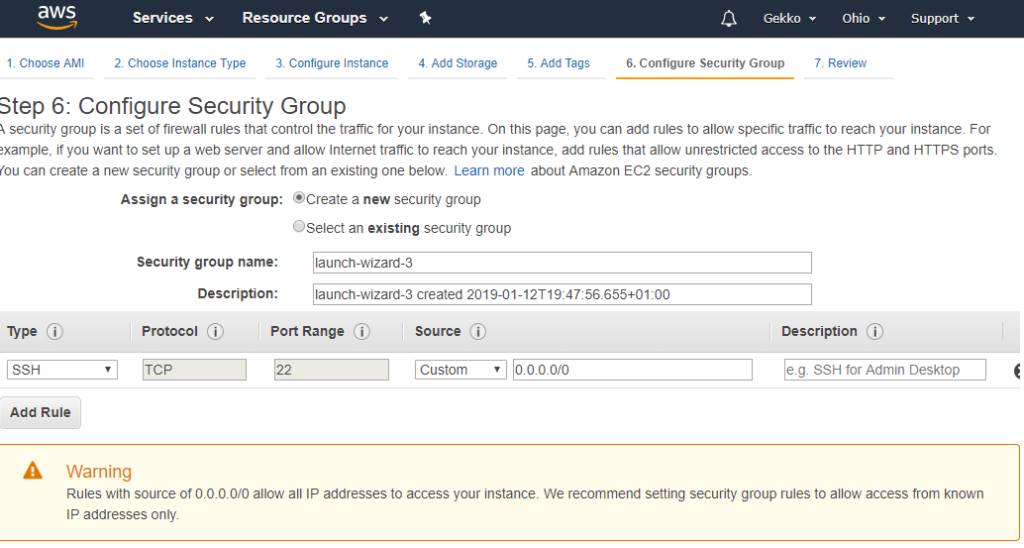
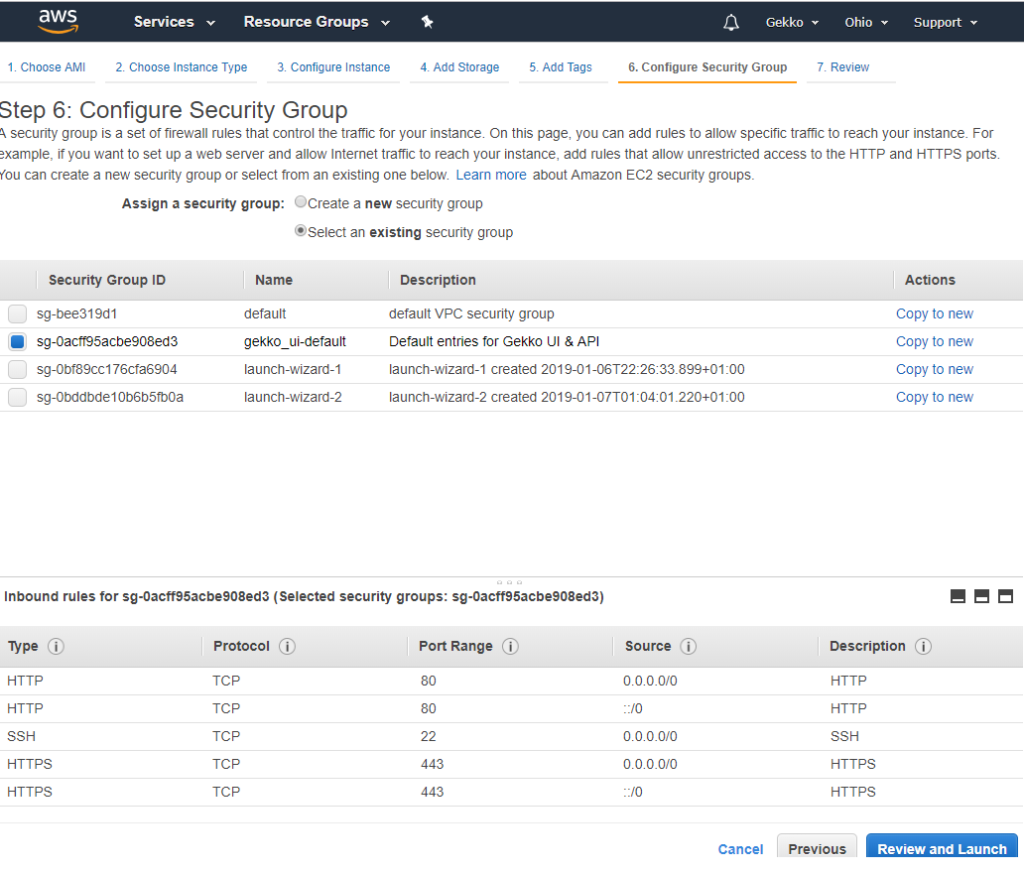
L’écran suivant présente un aperçu global avant la création et le lancement de la machine virtuelle par Amazon. Je ne vais pas le copier/coller, mais cliquez sur « Launch » (Lancer) en bas.
L’étape suivante est une ÉTAPE CRITIQUE. Amazon va créer des clés SSH que vous devrez conserver et utiliser pour vous connecter à la machine virtuelle via SSH. Ne les perdez pas. Vous pourrez utiliser exactement la même clé pour les autres machines virtuelles que vous souhaiterez créer, une seule clé pouvant donc correspondre à toutes vos machines virtuelles.
Comme j’en ai déjà généré une pour mon autre VM (appelée gekko), je la réutilise.
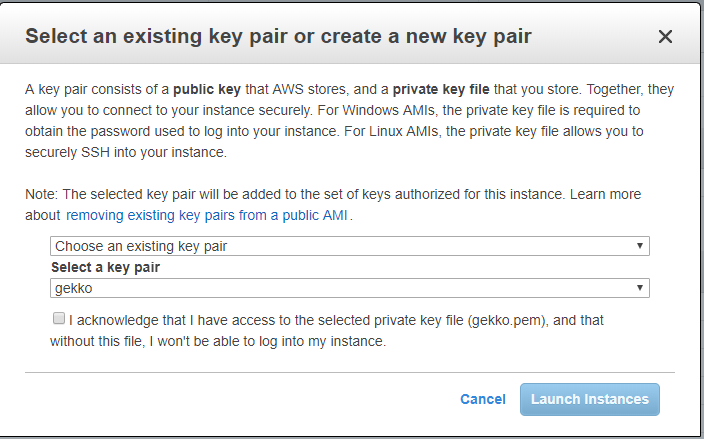
Et ensuite, une simple page d’état explique que l’instance est en cours de lancement et renvoie vers quelques pages de documentation, que vous devriez bien sûr lire.
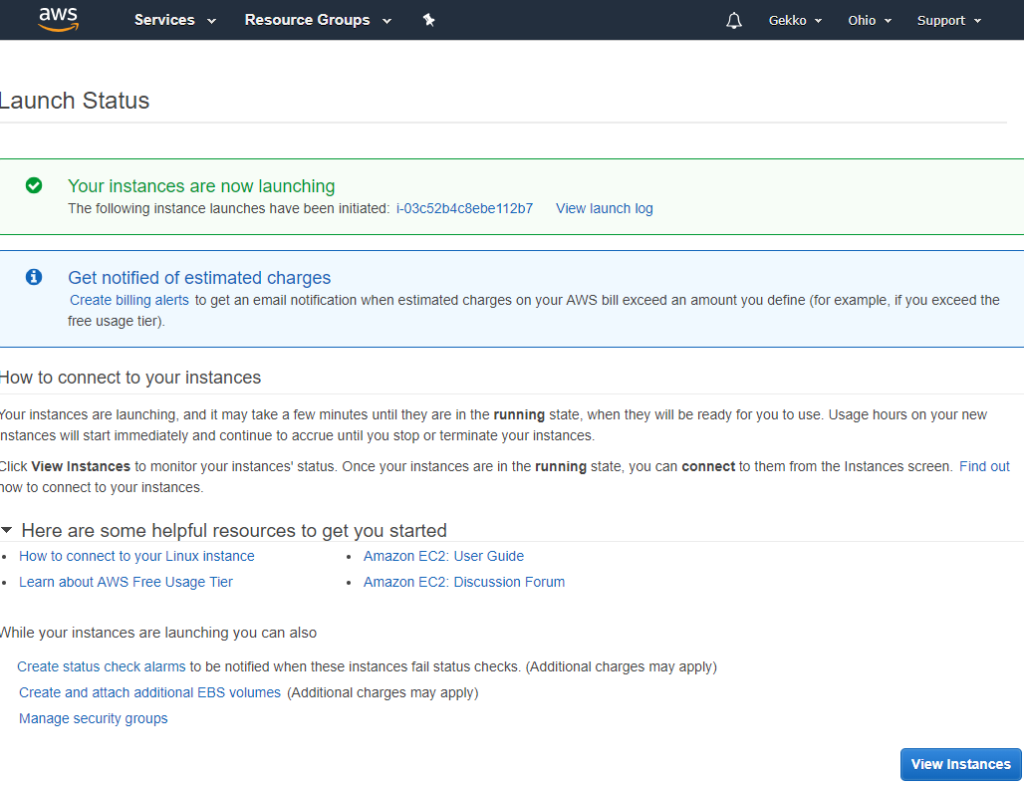
Étape 2 : connexion à distance à l’instance
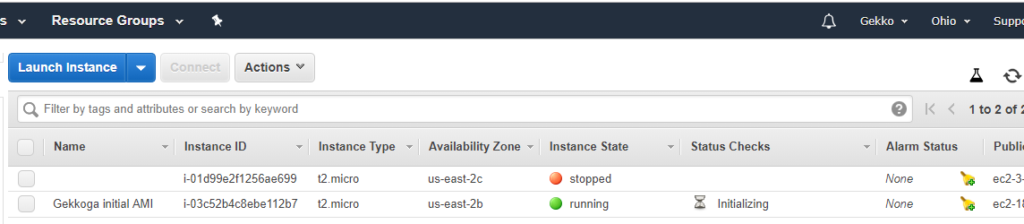
Lorsque nous cliquons sur le bouton bleu « View instances » (Afficher les instances), nous sommes redirigés vers la console EC2 (vous l’utiliserez beaucoup) et nous pouvons voir que notre nouvelle instance est lancée, et que son nom correspond à la balise que nous avons définie précédemment lors de la configuration (vous voyez également mon autre machine virtuelle de test, qui n’a pas de tag pour la nommer, qui est arrêtée).
Ensuite, nous allons nous connecter au shell de la VM via SSH. Sur mon ordinateur portable sous Windows, j’utiliserai Putty. Je suppose que vous avez téléchargé votre clé privée créée précédemment sur la console Amazon. Avec Putty, le fichier PEM doit être converti à l’aide de PuttyGen afin de générer un fichier .ppk utilisable.
Vous devrez également copier l’adresse IPv4 publique depuis la console EC2. Il vous suffit de sélectionner votre instance et de récupérer la valeur affichée dans le champ « Adresse IPv4 publique ».
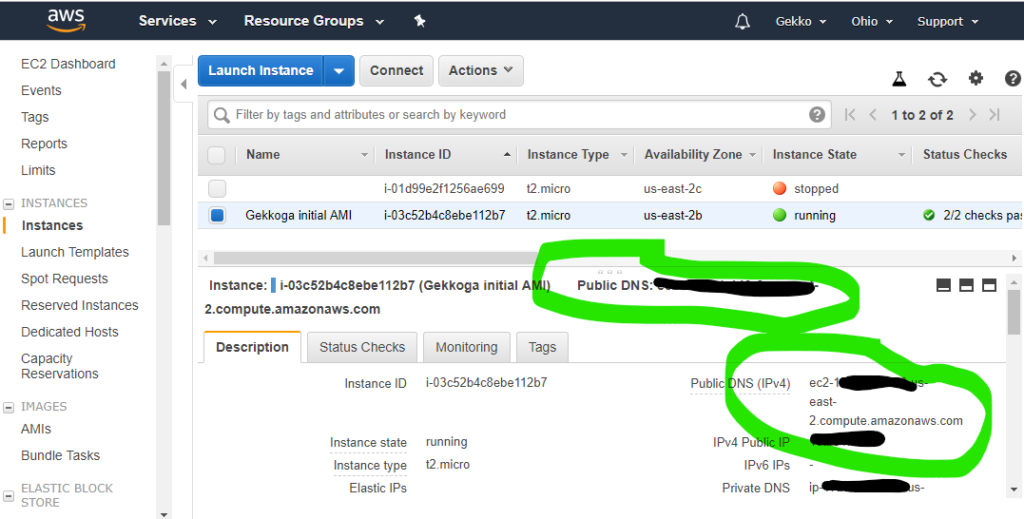
Maintenant, dans Putty, il vous suffit d’enregistrer une session avec votre clé privée .ppk configurée et ec2-user@<nom d’hôte public récupéré depuis la console> comme hôte. Gardez à l’esprit que ce nom d’hôte et l’adresse IP associée peuvent changer (et changeront probablement). Si vous ne parvenez plus à vous connecter à votre VM, la première chose à faire est de vérifier son nom d’hôte dans votre console EC2. Nous automatiserons cette opération ultérieurement.
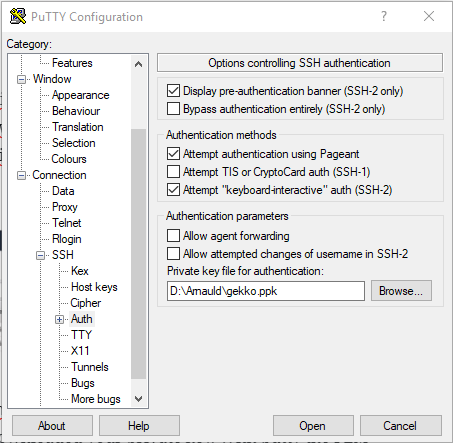
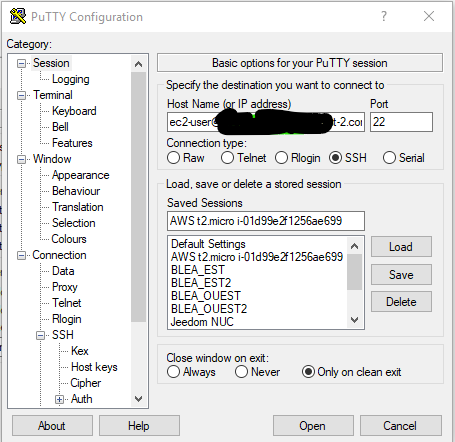
Nous lançons la session. Putty vous demandera si vous souhaitez faire confiance à l’hôte, cliquez sur Oui.
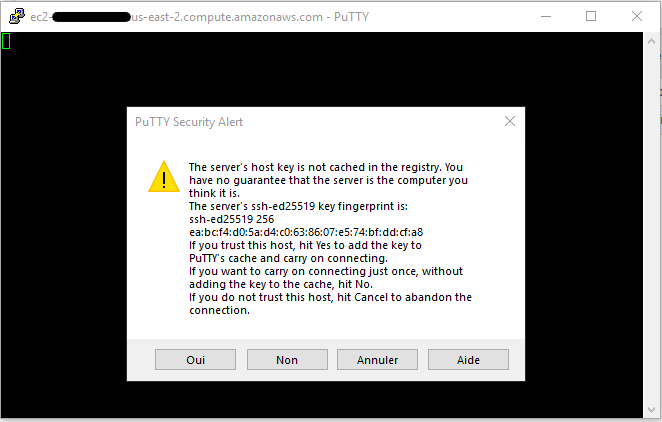
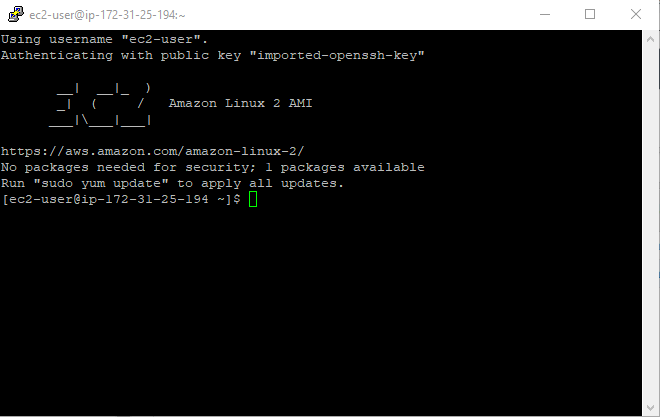
Voila, nous sommes connectés ! C’était rapide et simple.
Étape 3 : mise à jour de la VM et déploiement de nos logiciels
Nous devons maintenant déployer tous les éléments de base que nous avons vus dans les articles précédents, mais aussi d’autres éléments tels que NGinx pour protéger l’accès à l’interface utilisateur de Gekko. Plus tard, nous verrons comment la VM peut télécharger et mettre à jour automatiquement les stratégies à chaque démarrage, afin de garantir que tout reste à jour avant l’exécution.
L’objectif est de déployer tout ce dont nous avons besoin pour lancer une machine virtuelle Gekkoga fonctionnelle, puis nous allons « capturer » cette machine virtuelle afin de créer une AMI personnalisée, qui pourra être réutilisée sur une meilleure machine virtuelle, spécialisée dans les calculs CPU. Notez qu’EC2 peut également fournir des machines virtuelles avec du matériel spécifique comme des GPU si vous avez besoin d’exécuter des logiciels capables de décharger le calcul sur des cartes GPU. Ce n’est malheureusement pas notre cas ici, mais cela pourrait l’être un jour, car j’aimerais commencer à expérimenter l’IA.
Vous trouverez ci-dessous les commandes bash que j’ai utilisées, étape par étape. La plupart d’entre elles sont reprises de mes articles précédents sur Gekko & Gekkoga. Vous pouvez utiliser les liens vers mes fichiers pour télécharger quelques éléments standard (sans compromettre votre sécurité), mais certaines parties privées devront être modifiées par vos soins, en particulier la connexion ssh à votre serveur « commande & contrôle » domestique, bien sûr.
Nous commençons par mettre à jour la VM et déployer les éléments génériques.
#############################
### AWS AMI General Setup ###
#############################
##Base packages
#general OS updates
sudo yum update -y
sudo yum install curl wget git -y
#Declare & activate an additional repo for third parties software
sudo wget -r --no-parent -A 'epel-release-*.rpm' http://dl.fedoraproject.org/pub/epel/7/x86_64/Packages/e/
sudo rpm -Uvh dl.fedoraproject.org/pub/epel/7/x86_64/Packages/e/epel-release-*.rpm
sudo yum-config-manager --enable epel*
#My favorite text editor
sudo yum install joe -y
##install npm & nodejs
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.33.11/install.sh | bash
source ~/.bashrc
nvm install node
#install pm2
npm install pm2 -g
#Allow pm2 to restart at boot time, by using 'pm2 save' to save running sessions
sudo env PATH=$PATH:/home/ec2-user/.nvm/versions/node/v11.6.0/bin /home/ec2-user/.nvm/versions/node/v11.6.0/lib/node_modules/pm2/bin/pm2 startup systemd -u ec2-user --hp /home/ec2-user
############################
#### Gekko installation ####
############################
#gekko & PM2 launch script
git clone git://github.com/askmike/gekko.git -b stable && cd gekko
#do NOT run npm audit fix as suggested by npm or you will break Gekko
npm install --only=production
cd exchange && npm install --only=production && cd ..
#Install emailjs if you want to activate mails notifications
npm install emailjs
#Create a startup script for UI
echo '#!/bin/bash' > start_ui.sh
echo "rm ui_logs/" >> start_ui.sh
echo "pm2 start gekko.js --name gekko_ui --log-date-format="YYYY-MM-DD HH:mm Z" -e ui_logs/ui_err.log -o ui_logs/ui_out.log -- --ui max_old_space_size=8096" >> start_ui.sh
chmod 755 start_ui.sh
#Download some kraken history for EUR/ETH
wget https://blog.sinecu.re/files/backup_0.1.db
mkdir history
mv backup_0.1.db history/kraken_0.1.db
#Update Gekko's UI conf with extended timeouts
cd $HOME
wget https://blog.sinecu.re/files/gekko_confUI.tgz
tar zxfp gekko_confUI.tgz && rm gekko_confUI.tgz
############################
### GekkoGA installation ###
############################
git clone https://github.com/gekkowarez/gekkoga.git && cd gekkoga
#Install the fix to handle Gekko v0.6x new API
git fetch origin pull/49/head:49 && git checkout 49
#download the fix to flatten parameters and fix mutation
mv index.js index.js.orig
curl -L -O https://raw.githubusercontent.com/gekkowarez/gekkoga/stable/index.js
#download the fix to support nested config-parameters
mv package.json package.json.orig
curl -L -O https://raw.githubusercontent.com/gekkowarez/gekkoga/stable/package.json
#Install it, but don't run npm audit fix as requested by the line below or it will break everything !
npm install
#Install emailjs if you want to activate mails notifications
npm install emailjs
#create a PM2 script
echo '#!/bin/bash' > start.sh
echo "rm logs/" >> start.sh
echo "pm2 start run.js --name gekkogaMyMACD --log-date-format="YYYY-MM-DD HH:mm Z" -e logs/err.log -o logs/out.log -- -c config/config-MyMACD-backtester.js max_old_space_size=8192" >> start.sh
chmod 755 start.sh
cd $HOMEEnsuite, nous déployons NGinx qui agira comme un proxy inverse (reverse proxy) pour authentifier les requêtes adressées à l’interface utilisateur de Gekko. Attention aux lignes 8 et 15 : certains éléments doivent être configurés en fonction de votre propre configuration.
###########################################################################
## Deploy & configure Nginx for Reverse Proxy setup in front of Gekko UI ##
###########################################################################
#install nginx
sudo amazon-linux-extras install nginx1.12 -y
sudo service nginx stop
#You need to change your host inside nginx.conf, IT IS CONFIGURED FOR MY DOMAIN, CUSTOMIZE IT
wget https://blog.sinecu.re/files/nginx.conf
sudo mv ./nginx.conf /etc/nginx/nginx.conf
#certbot certificate generation, thanks to https://coderwall.com/p/e7gzbq/https-with-certbot-for-nginx-on-amazon-linux
sudo yum install -y certbot python2-certbot-apache
#beware the script downloaded below IS CONFIGURED FOR MY DOMAIN, CUSTOMIZE IT
wget https://blog.sinecu.re/files/cli.ini
sudo mv cli.ini /etc/letsencrypt/
#Here be sure that ports 80 and 443 are mapped to your instance in your EC2 Security Group
#And the FQDN you previously changed in cli.ini needs to point on your EC2 IP ! Will fail otherwise.
#If you have troubles please read certbot docs as there are other ways to generate a certificate
sudo certbot certonly
#run a daily crontab to eventually renew our certificate
wget https://blog.sinecu.re/files/certbot-renewal
sudo mv certbot-renewal /etc/cron.daily/À partir de là, les choses deviennent un peu plus complexes : il est recommandé d’avoir des compétences de base en administration système. Ne vous inquiétez pas, je vais vous expliquer brièvement chaque étape pour plus de clarté.
- Créer un utilisateur/mot de passe à utiliser par le proxy inverse Nginx
sudo printf "USERNAME_TO_CHANGE:$(openssl passwd -crypt PASSWORD_TO_CHANGE!)n" > /etc/nginx/.htpasswd- Pour automatiser le téléchargement de fichiers depuis notre serveur « commande et contrôle » domestique à l’aide de scp ou automatiser le lancement d’actions sur notre serveur domestique via ssh (pour créer automatiquement une archive tarball des stratégies de notre gekko avant de les télécharger, par exemple), nous devons importer la clé SSH de notre serveur domestique/utilisateur dans /home/ec2-user/.ssh/ et modifier ses permissions avec
chmod 600.
- Une fois la clé SSH de votre serveur domestique importée (n’oubliez pas de définir des autorisations sécurisées avec
chmod 600), utilisez les commandes suivantes pour synchroniser votre répertoire Gekko entre vos environnements local et EC2 :
##Sync Gekko strats & scripts with the one on my local/home server mainly use for dev and quick testing (REQUIRES SSH AUTHENT TO BE SETUP BETWEEN BOTH HOSTS)
#nota: We could use rsync too
cd $HOME
ssh <user>@<fqdn> tar czfp gekko_strats.tgz gekko/SECRET-api-keys.json gekko/config gekko/.sh gekko/.js gekko/strategies gekko/gekkoga
scp <user>@<fqdn>:/home/gekko/gekko_strats.tgz ./
tar zxfp gekko_strats.tgz
rm gekko_strats.tgz
cd gekko && ./start_ui.sh- Nous devons maintenant lancer nginx… et activer le service afin qu’il soit relancé au démarrage. Nous allons également enregistrer les sessions pm2, puisque nous avons démarré gekko avec notre script start_ui.sh dans les commandes ci-dessus. De cette façon, pm2 le redémarrera également au moment du démarrage de la VM.
sudo systemctl enable nginx
sudo systemctl start nginx
pm2 saveÉtape 4 : tester Gekko sur la machine virtuelle
Si tout s’est bien passé, vous devriez pouvoir lancer votre navigateur Web préféré et vous rendre à l’adresse https://<Votre FQDN VM EC2> pour voir s’afficher une invite de connexion. Vous devez saisir le nom d’utilisateur et le mot de passe que vous avez définis (étape 3) dans /etc/nginx/.htpasswd.
Vous devriez maintenant voir ceci…Vous devriez maintenant voir ceci…

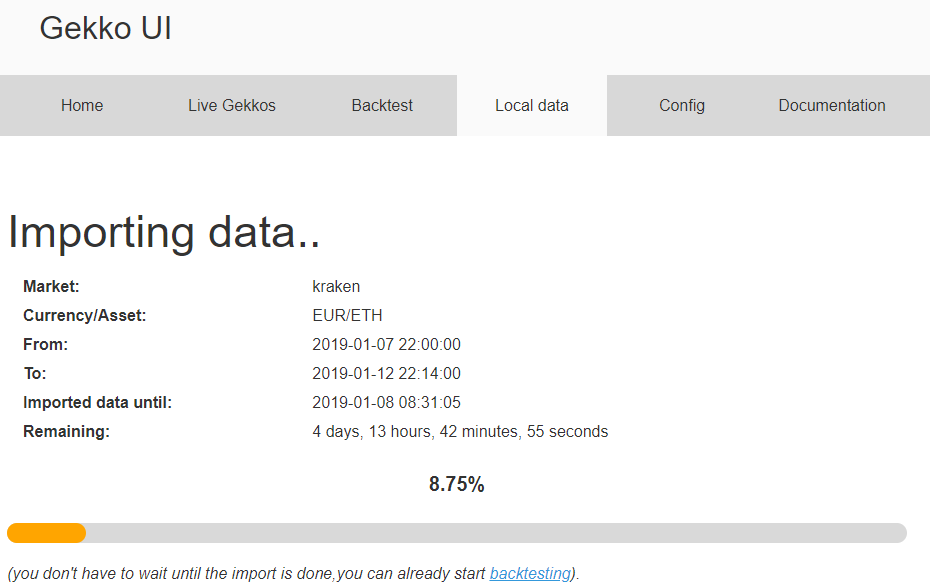
Mon ensemble de données de test a été correctement téléchargé, il est bien détecté par Gekko. Je vais simplement le mettre à jour en demandant à Gekko de télécharger les données depuis le 07/01/2019 à 22h30 jusqu’à maintenant, puis de les télécharger à nouveau sur mon serveur de référence à domicile.
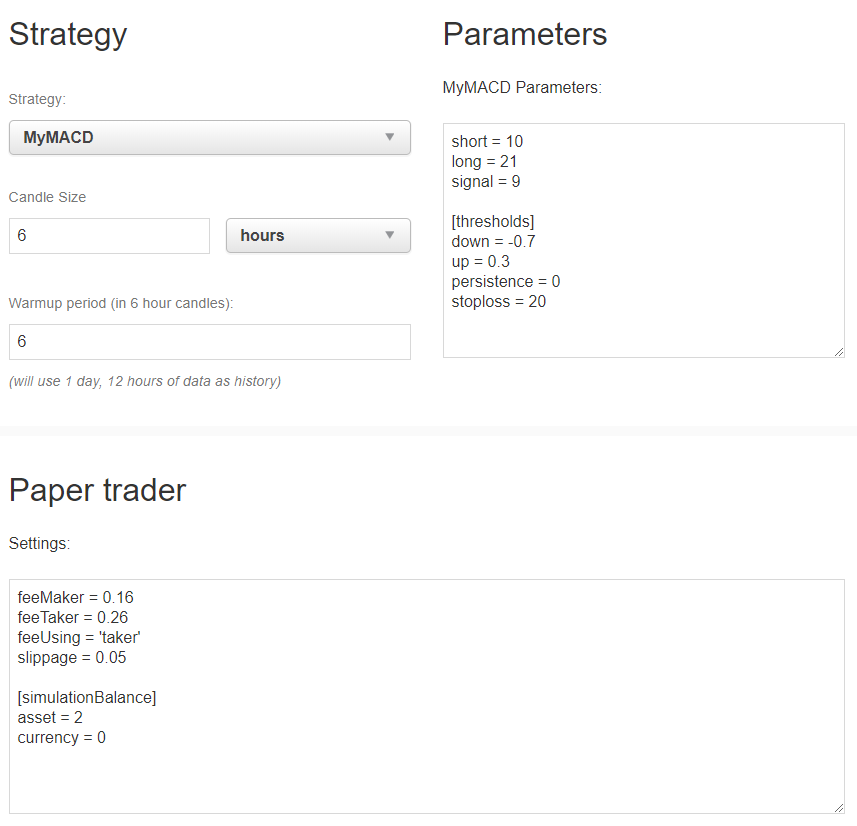
Ensuite, essayons la stratégie que nous avons téléchargée depuis notre serveur de référence, à domicile.
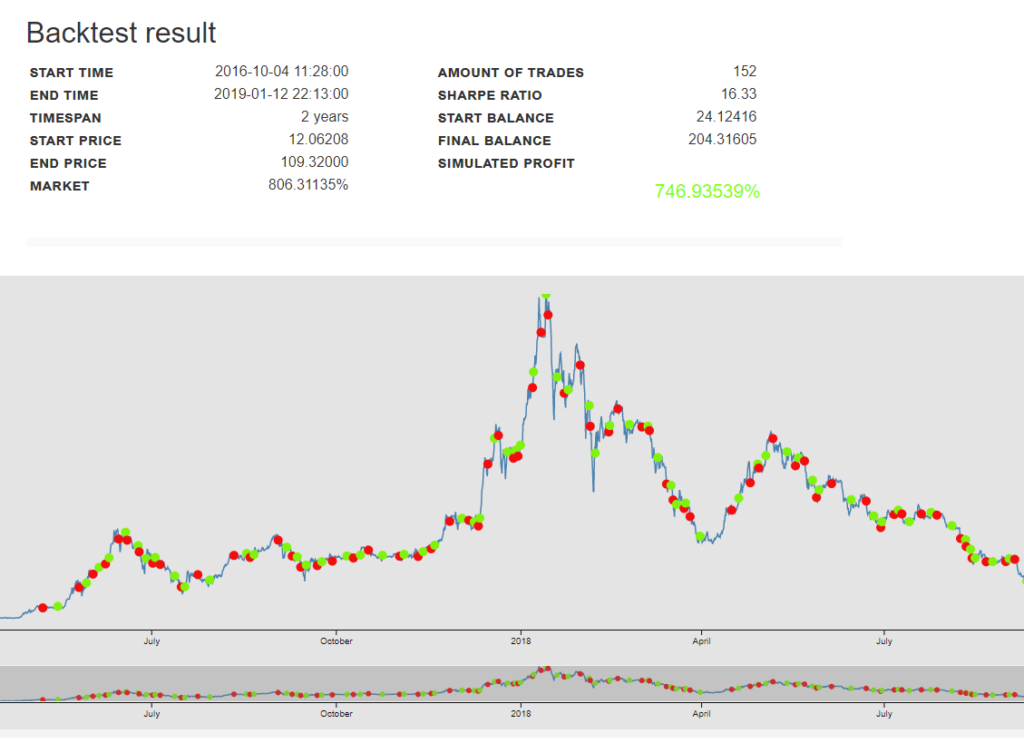
Tout fonctionne bien… Nous disposons désormais d’une bonne base pour cloner cette machine virtuelle et en faire un modèle AMI pour des machines virtuelles plus haut de gamme. Nous devrons la rendre:
- Capable de télécharger les données actualisées des marchés
- Capable de télécharger les stratégies actualisées depuis notre serveur de référence@home
- Capable de lancer un script de démarrage Gekkoga particulier
- Capable de télécharger ou d’envoyer les résultats à notre serveur de référence@home
Note: N’oubliez pas d’arrêter votre machine virtuelle à partir de la ligne de commande ou de la console Amazon EC2 afin qu’elle n’épuise pas tous vos crédits de temps de fonctionnement «gratuits» !
Étape 5 : utiliser la ligne de commande AWS depuis notre serveur domestique
Nous devons installer la CLI AWS (Command Line Interface) sur notre serveur « command & control » local/domestique. J’ai d’abord dû installer pip pour Python.
sudo apt-get install python-pipNous pouvons désormais installer la CLI AWS à l’aide de pip, comme expliqué dans la documentation d’Amazon. L’option –user l’installera dans votre répertoire utilisateur $HOME.
pip install awscli --upgrade --userNous ajoutons le répertoire binaire AWS local à notre PATH utilisateur afin de pouvoir le lancer sans avoir à utiliser son chemin complet. J’utilise une AMI basée sur Debian, je vais donc l’ajouter dans .profile.
cd $HOME
echo 'export PATH=~/.local/bin:$PATH' >> .profileMaintenant, nous devons créer un utilisateur et des groupes « Admin » IAM (Identity & Access Management) à partir de notre console EC2, afin de pouvoir utiliser les outils AWS en ligne de commande. Veuillez suivre la documentation d’Amazon « Création d’un utilisateur et d’un groupe IAM administrateur (console) ». En gros, vous allez créer un groupe, une politique de sécurité et un utilisateur administrateur. À la fin, vous devez obtenir et utiliser un identifiant de clé d’accès et une clé d’accès secrète pour votre utilisateur administrateur. Si vous les perdez, vous ne pourrez pas les récupérer, mais vous serez bons pour perdre du temps à en recréer une nouvelle pour cet utilisateur à partir de la console EC2 (et propager la modification sur tous les systèmes qui l’utilisent). Veillez donc à conserver ces clés en lieu sûr.
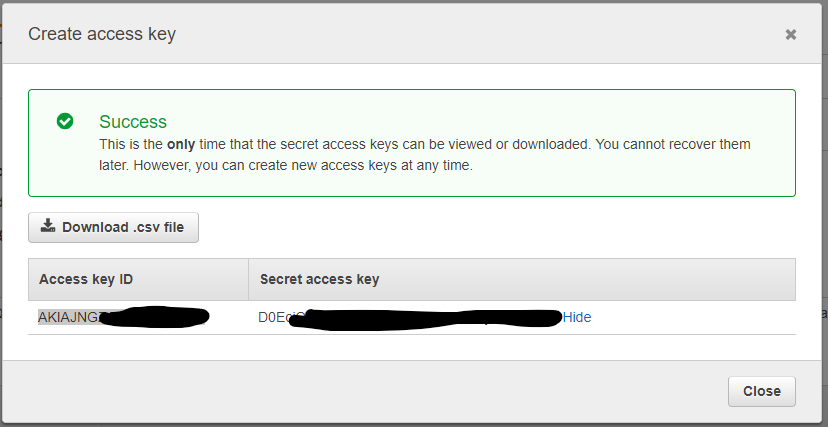
Nous utiliserons ensuite ces clés sur notre VM et sur notre serveur « command & control » domestique à partir duquel nous souhaitons contrôler nos instances. Vous pouvez également spécifier la région qu’Amazon vous a attribuée si vous le souhaitez mais ce n’est pas indispensable (astuce : n’utilisez pas la lettre à la fin de la région, par exemple si votre VM fonctionne dans us-east-2c, entrez « us-east-2 »).


Testons tout cela avec quelques exemples tirés de la documentation :
- Récupérer une liste JSON de toutes nos instances, avec quelques clés/valeurs demandées (vous vous souvenez des balises que nous pouvons définir dans la console EC2 lorsque nous créons une machine virtuelle ?) :
aws ec2 describe-instances --query 'Reservations[].Instances[].[InstanceId,State.Name,Tags[?Key==`Name`] | [0].Value]'
- Arrêter une instance (ou plusieurs) … Absolument indispensable pour ne pas dépenser tous nos jetons gratuits, ou être facturé beaucoup plus que ce que nous utiliserons réellement avec des machines virtuelles plus grandes. Notez que nous réutilisons ici l’ID obtenu via la ligne de commande ci-dessus.
aws ec2 stop-instances --instance-ids <instanceId>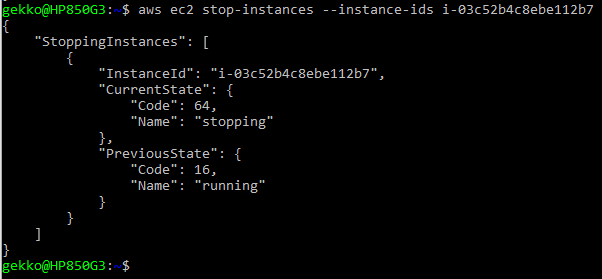
- Démarrer une instance à partir de son identifiant (nous pouvons en démarrer plusieurs)
aws ec2 start-instances --instance-ids <instanceId>
- Demander l’adresse IP publique de notre machine virtuelle en cours d’exécution (nous devons connaître son InstanceID, nous pouvons en obtenir plusieurs) :
aws ec2 describe-instances --instance-ids <instanceId> --query 'Reservations[*].Instances[*].PublicIpAddress' --output text
- Pour envoyer des commandes shell Linux à distance (et non AWS CLI) à exécuter sur une machine virtuelle spécifique, vous devez créer un nouveau rôle IAM dans votre console EC2 et configurer votre machine virtuelle pour qu’elle l’utilise, afin que vos appels à distance soient autorisés.
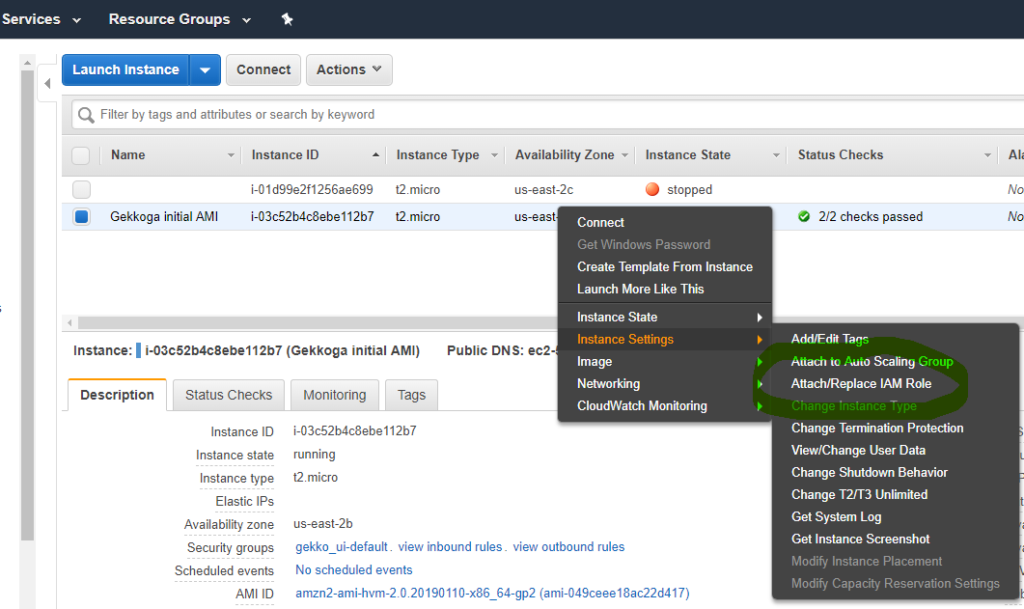
Attribuez à votre VM le rôle IAM avec le groupe Administrateur que vous avez défini précédemment, et dans lequel se trouve également l’utilisateur Administrateur que nous utilisons pour les clés AWS CLI. Nous devrions désormais pouvoir accéder à la VM, lui envoyer des informations et lui demander des données.
- Pour que la machine virtuelle exécute « ifconfig », nous lançons une première requête CLI et nous devons vérifier le CommandID renvoyé lors de ce premier appel :
aws ssm send-command --instance-ids <instanceId> --document-name "AWS-RunShellScript" --comment "IP config" --parameters commands=ifconfig
- Pour vérifier la sortie, nous utilisons le commandID dans une autre requête :
aws ssm list-command-invocations --command-id "69245d54-3be9-483f-981a-00af7abd2004"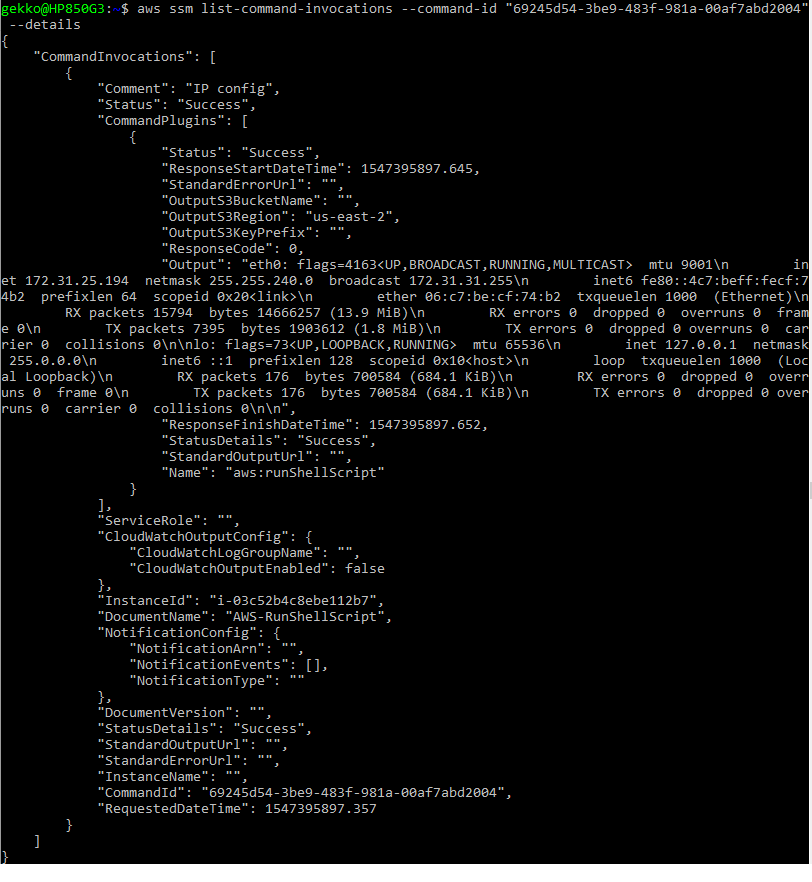
- Et… -pris dans la doc, j’ai juste ajouté le jq à la fin-, si nous voulons combiner les deux requêtes :
sh_command_id=$(aws ssm send-command --instance-ids "<instanceId>" --document-name "AWS-RunShellScript" --comment "IP config" --parameters commands='ifconfig' --output text --query "Command.CommandId") sh -c 'aws ssm list-command-invocations --command-id "$sh_command_id" --details --query "CommandInvocations[].CommandPlugins[].{Status:Status,Output:Output}"' | jq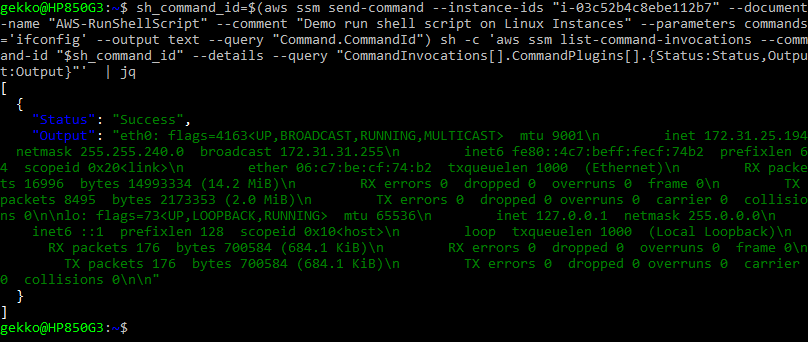
Notez qu’avec l’interface CLI, nous pouvons également simuler l’exécution de scripts bash en envoyant leur contenu via les paramètres send-command, comme expliqué au chapitre 5 ici.
Étape 6 : créer une nouvelle AMI à partir de notre VM de base
Nous arrêtons d’abord notre machine virtuelle de base en cours d’exécution.
aws ec2 stop-instances --instance-ids i-03c52b4c8ebe112b7Maintenant, dans la console EC2, nous allons créer une nouvelle AMI à partir de notre instance (documentation officielle).
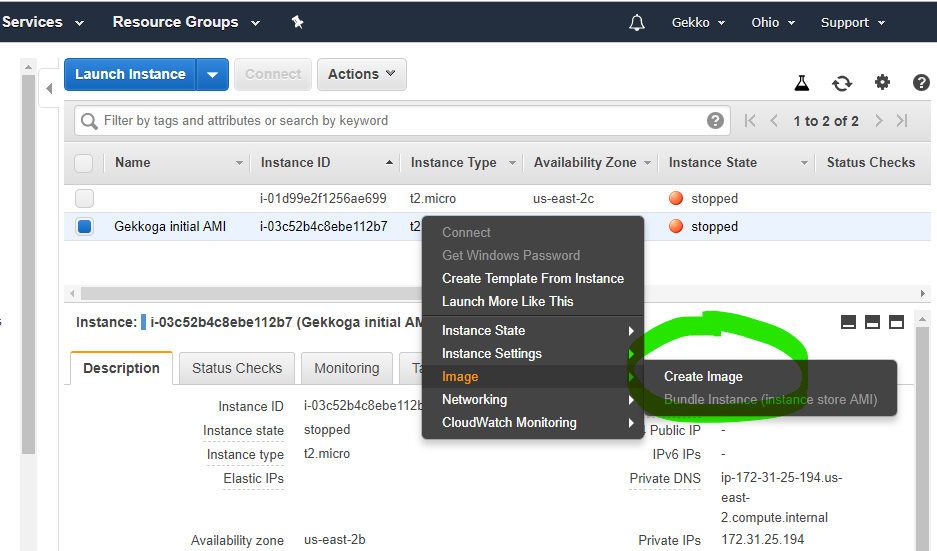
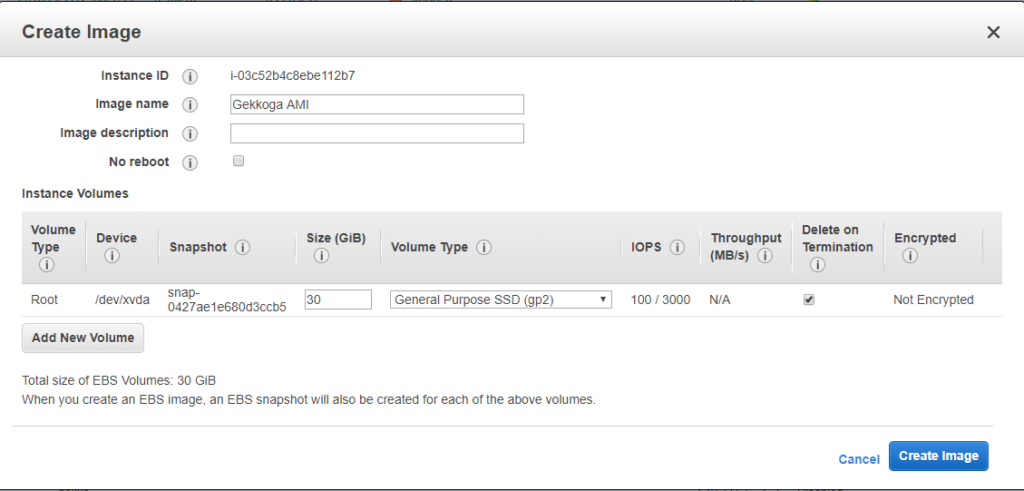
Une fois que vous avez cliqué sur « Créer une image », le tableau de bord vous indiquera son nouvel identifiant, que nous utiliserons plus tard pour lancer de nouvelles instances. Par défaut, les images que vous créez sont privées, mais vous pouvez modifier ce paramètre si vous le souhaitez et partager votre AMI avec la région que vous utilisez dans le cloud Amazon.
La vue d’ensemble: le scénario de déploiement complet
Le scénario est simple : depuis notre serveur domestique de commande et de contrôle, nous demandons d’abord la création d’une instance basée sur cette image, puis nous lançons et arrêtons notre VM à distance.
Lorsqu’une nouvelle instance est créée, nous souhaitons qu’elle exécute automatiquement un script au démarrage, à l’aide de la fonction « données utilisateur« , afin de télécharger les dernières données depuis notre serveur de commande et de contrôle. Les données utilisateur ne sont rien d’autre qu’un script shell qui s’exécute une seule fois. Ce processus est très bien documenté par Amazon. Le script « données utilisateur » ne s’exécutent qu’une seule fois, lors du tout premier démarrage de votre instance nouvellement créée, et non lors des démarrages suivants.
Par conséquent, nous devrons également inclure un élément supplémentaire pour que notre instance exécute certaines tâches à chaque démarrage : nous utiliserons un script /etc/rc.local basique qui utilisera rsync pour télécharger l’intégralité du répertoire d’installation de Gekko depuis notre serveur de commande et de contrôle, le modifier légèrement, puis lancer Gekkoga.
Nous devrons également créer un script en arrière-plan afin de surveiller attentivement les indicateurs d’Amazon concernant l’arrêt imminent de notre instance. Les instances Spot sont automatiquement arrêtées par Amazon, et il y a au maximum deux minutes de délai entre l’avis de résiliation et l’arrêt effectif. Ce point sera détaillé dans le prochain article.
The whole process is:
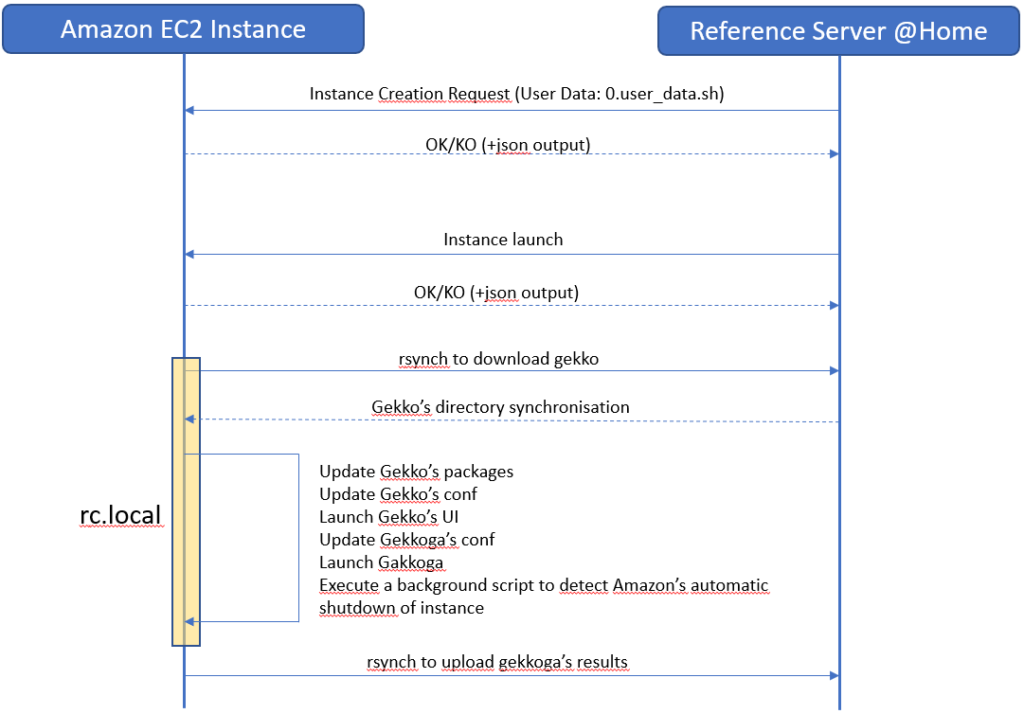
Étape 7 : Instanciation et exécution des actions au premier démarrage
Nous voulons indiquer à une nouvelle instance de cette image d’exécuter un script shell lors de son tout premier démarrage. Nous allons d’abord créer ce script sur notre serveur de commande et de contrôle local et y ajouter quelques commandes, mais aussi activer la journalisation sur la VM (les sorties seront disponibles à la fois dans /var/log/user-data.log et dans /dev/console).
Tout d’abord, je crée un script « minimal » appelé 0.user_data.sh dans un répertoire $HOME/AWS sur mon serveur de commande et de contrôle, et j’y insère ceci :
#!/bin/bash
exec >> >(tee /var/log/gekko_packages.log | logger -t user-data -s 2>/dev/console) 2>&1
d=$(date +%Y%m%d_%H%M%S)
echo "===== Entering Gekko User Data First Boot Execution ====="
echo "$d"
echo "===== End of Gekko User Data First Boot Execution ====="Ensuite, je demande la création et le lancement d’une nouvelle instance basée sur notre nouvel ID d’image. Notez que j’utilise le nom de la clé que j’ai définie précédemment (gekko), j’ai utilisé le même sous-réseau que ma VM précédente (je ne sais pas vraiment si cela est obligatoire, je dois tester), l’ID du groupe de sécurité peut être vérifié dans le menu « Security Groups » de la console EC2, et nous spécifions également le rôle IAM que nous voulons autoriser à contrôler la VM avec AWS CLI (vous l’avez créé précédemment car il était obligatoire pour l’exécution de certaines commandes CLI).
Notez également que nous transmettons notre script bash 0.user_data.sh créé précédemment en tant que paramètre : son contenu sera transmis à Amazon, qui le lancera au premier démarrage de l’instance. Si vous souhaitez qu’une action soit effectuée au tout premier démarrage, pensez simplement à l’ajouter dans ce script.
aws ec2 run-instances --image-id ami-04cff54098caebe78 --count 1 --instance-type t2.micro --key-name gekko --security-group-ids sg-0acff95acbe908ed3 --iam-instance-profile Name="Administrator" --tag-specifications 'ResourceType=instance,Tags=[{Key=Name,Value=Gekkoga Test 1}]' --user-data file://0.user_data.sh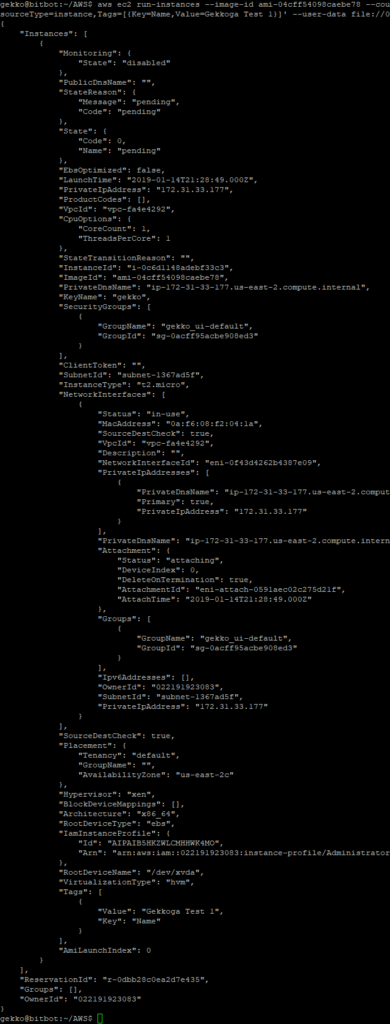
Nous pouvons voir que notre nouvel InstanceId est i-0c6d1148adebf33c3 . Depuis la console EC2, je peux voir que la VM est lancée. Je souhaite maintenant vérifier si mon script user-data a été exécuté.
aws ec2 get-console-output --instance-id i-0c6d1148adebf33c3 --output text | grep user-data:
C’est pas mal ! J’ai également vérifié plusieurs fois sur mon serveur de référence si je pouvais voir les connexions ssh entrantes en ajoutant une commande d’exécution ssh + une commande de demande de téléchargement scp au script, et tout fonctionne : 2 connexions comme prévu (une pour le ssh, l’autre pour le scp).
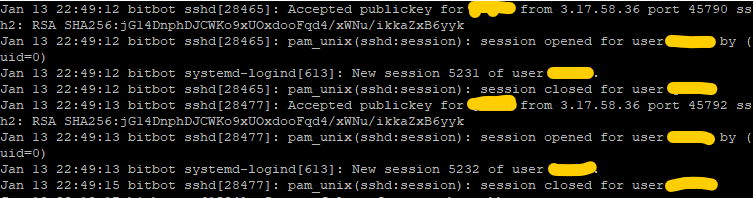
Nous disposons d’un « script initial » fonctionnel que la VM exécutera lors de sa première instanciation et que nous pourrons personnaliser ultérieurement afin d’effectuer des actions spécifiques ponctuelles. Nous souhaitons désormais que notre VM se connecte à notre serveur de référence à chaque démarrage afin de préparer un paquet, puis de le télécharger, de le décompresser et d’exécuter un script start.sh qui pourrait y être intégré.
Étape 8 : télécharger, customiser et lancer une installation Gekko+GekkoGA à chaque démarrage.
Tout d’abord, sur notre machine virtuelle EC2 de référence (celle à partir de laquelle nous avons créé une nouvelle AMI, donc soit nous devrons créer une nouvelle AMI ultérieurement, soit vous pouvez effectuer cette étape pendant que vous préparez encore la première AMI), nous allons procéder comme suit :
cd $HOME
sudo chmod +x /etc/rc.d/rc.local
mkdir AWS
mkdir AWS/logs
mkdir AWS/logs/old
mkdir AWS/archivesEnsuite, nous allons modifier /etc/rc.local (qui est un lien symbolique vers /etc/rc.d/rc.local) et ajouter ceci. Attention, vous devez modifier quelques lignes (22 et 25) pour atteindre votre propre serveur de commande et de contrôle :
# Needed to use pm2 at boot time
export NVM_DIR="/home/ec2-user/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && . "$NVM_DIR/nvm.sh" # This loads nvm
[ -s "$NVM_DIR/bash_completion" ] && . "$NVM_DIR/bash_completion" # This loads nvm bash_completion
d=$(date +%Y%m%d_%H%M%S)
#save every output in a dated logfile & system console
exec >> >(tee /home/ec2-user/AWS/logs/${d}_package.log | logger -t user-data -s 2>/dev/console) 2>&1
echo "===== Entering Gekko Packaging Retrieval ====="
echo "$d"
#Activates extended pattern matching features from Bash
shopt -s extglob
echo "Moving potential old logs to AWS/logs/old"
sudo mv /home/ec2-user/AWS/logs/!(${d}_package.log|old) /home/ec2-user/AWS/logs/old/
echo "moving potential old gekko dir to AWS/archives/"
su ec2-user -c "mv /home/ec2-user/gekko /home/ec2-user/AWS/archives/${d}_gekko"
echo "Safe remote backup of Command&Control_Server gekko's sqlite db"
su ec2-user -c ssh <YOUR_C2C_SERVER> "sqlite3 /home/gekko/gekko/history/kraken_0.1.db ".backup '/home/gekko/gekko/history/kraken_0.1.db.backup'""
echo "Syncing gekko's dir from remote Command&Control_Server ..."
su ec2-user -c "rsync -azh <YOUR_C2C_SERVER>:/home/gekko/gekko /home/ec2-user/"
echo "Replacing sqlite db with its safe backup"
su ec2-user -c "mv /home/ec2-user/gekko/history/kraken_0.1.db.backup /home/ec2-user/gekko/history/kraken_0.1.db"
echo "Tweak Gekko's UIconfig files ..."
su ec2-user -c cp -f /home/ec2-user/dist_UIconfig.js /home/ec2-user/gekko/web/vue/dist/UIconfig.js
su ec2-user -c cp -f /home/ec2-user/public_UIconfig.js /home/ec2-user/gekko/web/vue/public/UIconfig.js
echo "Relaunching Nginx ..."
sudo service nginx restart
echo "Rebuilding Gekko dependancies ..."
su ec2-user -c rm -rf /home/ec2-user/gekko/node_modules/*
su ec2-user -c "source /home/ec2-user/.bashrc && cd /home/ec2-user/gekko && npm install --only=production"
echo "Rebuilding GekkoGA dependancies ..."
su ec2-user -c "rm -rf /home/ec2-user/gekko/gekkoga/node_modules/*"
su ec2-user -c "source /home/ec2-user/.bashrc && cd /home/ec2-user/gekko/gekkoga && npm install"
echo "Launching Gekko's UI from /home/ec2-user/gekko/start_ui.sh ..."
su ec2-user -c "/home/ec2-user/gekko/start_ui.sh"
echo "Launching GekkoGA from /home/ec2-user/gekko/gekkoga/start_gekkoga.sh ..."
su ec2-user -c "/home/ec2-user/gekko/gekkoga/start_gekkoga.sh"
echo "Launching background script to handle termination events ..."
/etc/rc.termination.handling &
echo "Done."
echo "===== End of Gekko Packaging Retrieval ====="
exit 0Quelques commentaires :
- Au cours de mes tests, j’ai rencontré un problème avec sqlite, qui semble lié au type de plateforme utilisé. Pour éviter cela, je reconstruis automatiquement les dépendances après la synchronisation rsync.
- Je mets à jour les fichiers UIConfig car sur l’instance EC2, j’utilise NGinx, que je n’utilise pas sur mon serveur de référence @home.
- J’ai ajouté une ligne pour redémarrer NGinx, car j’ai remarqué que je devais le relancer manuellement avant de pouvoir accéder à l’interface utilisateur de Gekko. Je n’ai pas cherché à comprendre pourquoi, peut-être plus tard.
- Comme certains d’entre vous l’ont peut-être remarqué, nous synchronisons une installation Gekko distante dans un répertoire local $HOME/gekko. Par conséquent, dans le script, nous devons supprimer (ou déplacer) l’installation Gekko que nous avions précédemment effectuée sur notre instance EC2. Elle avait été déployée uniquement à des fins de test.
Sur notre serveur de référence @home :
- Nous créons un script $HOME/gekko/start_ui.sh qui contient, si ce n’est déjà fait (voir mes guides précédents) :
#!/bin/bash
cd $HOME/gekko
rm -rf ui_logs/*
pm2 start gekko.js --name gekko_ui --log-date-format="YYYY-MM-DD HH:mm Z" -e ui_logs/ui_err.log -o ui_logs/ui_out.log -- --ui max_old_space_size=8096- Nous créons un fichier $HOME/gekko/gekkoga/start_gekkoga.sh qui contient des instructions essentielles pour spécifier à GekkoGA :
- The strategy to optimize
- The number of CPU to use
#!/bin/bash
TOLAUNCH="config-MyMACD-backtester.js"
cd $HOME/gekko/gekkoga
# Get the number of CPU on the machine and reduce it by one to keep a little bit of responsibility
NBCPU=`getconf _NPROCESSORS_ONLN`
NBCPU="$(($NBCPU-1))"
NBCPU="parallelqueries: $NBCPU,"
# replace the number of concurrent threads in gekkoga's conf
sed -i "/parallelqueries:/c $NBCPU" config/config-MyMACD-backtester.js
# start Gekkoga !
rm -rf logs/*
pm2 start run.js --no-autorestart --name $TOLAUNCH --log-date-format="YYYY-MM-DD HH:mm Z" -e logs/err.log -o logs/out.log -- -c config/$TOLAUNCH max_old_space_size=8192Remarques :
- Vous ne devriez plus avoir à modifier le script start_ui.sh.
- Dans le script start_gekkoga.sh :
- Il vous suffit de modifier la variable TOLAUNCH et de lui passer le nom du fichier de configuration de votre Gekkoga à utiliser, c’est tout.
- Je voulais garder un vCPU libre pour gérer la synchronisation ou d’autres tâches requises par le système d’exploitation. Je vérifie donc dynamiquement le nombre de CPU sur la machine, je le réduit de 1 et je modifie la ligne correspondante dans le fichier de configuration de Gekkoga.
- Cela a un effet de bord: sur une machine à 1 CPU, ce qui est le cas des petites machines virtuelles EC2, cette valeur deviendra « 0 » et Gekkoga ne pourra pas démarrer, mais pm2 continuera d’essayer de le relancer. C’est pourquoi j’ai ajouté l’option pm2 « –no-autorestart » à ce script à la dernière ligne.
Nous redémarrons notre instance EC2 de référence :
aws ec2 reboot-instances --instance-ids i-03c52b4c8ebe112b7Après quelques secondes, nous vérifions le journal rc.local sur notre instance EC2 afin de vérifier la séquence de téléchargement de notre package de référence depuis notre serveur de contrôle et de commande. Dans rc.local, nous avons redirigé les journaux vers $HOME/AWS/logs/_package.log :
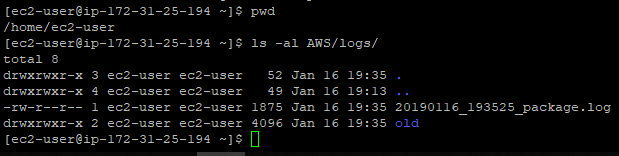
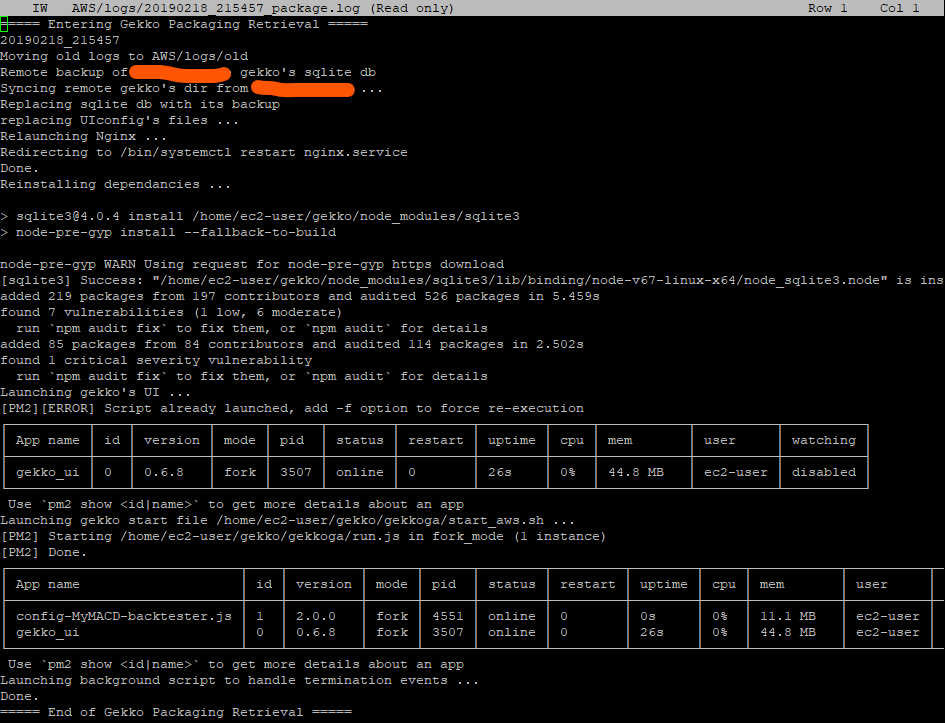
Tout semble fonctionner correctement. Vérifions l’état de pm2 :

L’erreur de Gekkoga est probablement normale, car comme vu précédemment, nous lui avons demandé de s’exécuter avec 0 requêtes parallèles… Vérifions ses journaux :
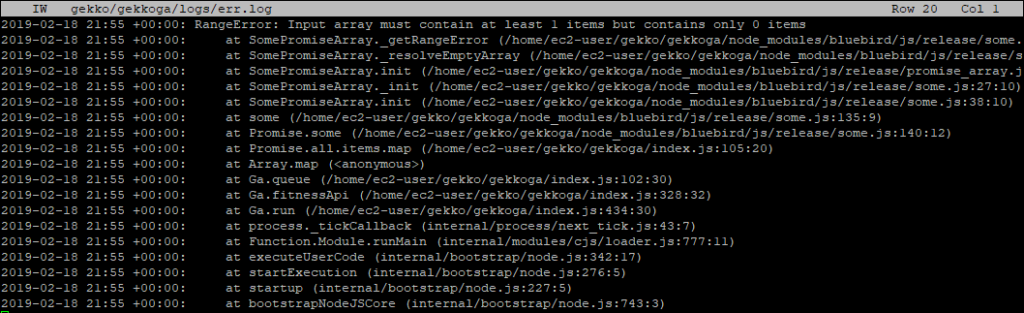

Et oui, je peux confirmer après un test rapide avec 0 requêtes parallèles sur mon serveur de référence @home que cette erreur se produit dans ce cas. Bien ! Cela devrait fonctionner avec plus de processeurs ou si nous modifions le fichier start_gekkoga.sh pour gérer ce cas particulier de « machine à un seul processeur ».
Une dernière chose, vérifions si l’interface utilisateur de Gekko est accessible à distance :
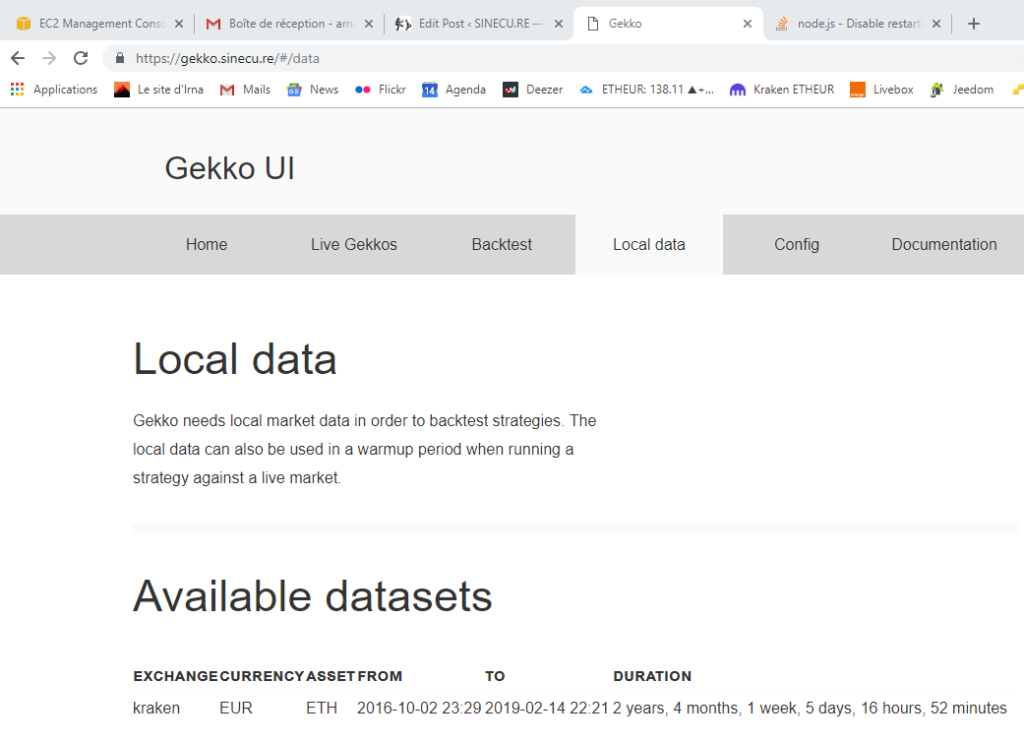
Seems Perfect !
Étape finale 9 : création d’une nouvelle AMI de référence
Maintenant, avant de créer une nouvelle version de notre AMI de référence (ce ne sera pas la dernière :)), je recommande de :
- Faire un peu de ménage dans AWS/logs, AWS/logs/old, mais aussi (sur mon serveur de référence @home) dans gekko/history, gekko/strategies et gekko/gekkoga/config et /gekko/gekkoga/results, car j’ai (et j’espère que vous aussi) effectué de nombreux tests.
- Ajouter un script shell pour mettre à jour automatiquement un DNS dynamique pointant vers la VM. Comme il s’agit à 99 % d’une utilisation personnelle, je ne vais pas entrer dans les détails ici. Ce script vérifie l’adresse IP externe de la machine, vérifie si elle est différente de la dernière connue, et si oui, met à jour l’enregistrement A du nom de domaine complet sur le serveur DNS.
La dernière étape consiste à créer une nouvelle MI de référence à partir de cette VM entièrement fonctionnelle. Vous connaissez la procédure, nous l’avons déjà effectuée ci-dessus, ainsi que pour l’instancier via votre AWS CLI installée chez vous.
La prochaine étape consistera à essayer de lancer une session de backtesting Gekkoga en instanciant notre AMI sur une machine virtuelle beaucoup plus performante en termes de CPU et de mémoire. Mais attention, cela vous sera facturé par Amazon !
Ce sera le sujet du prochain article.
Conclusion et ressources supplémentaires
Vous avez désormais mis en place un workflow évolutif et répétable pour lancer des environnements de test Gekko/Gekkoga dans le cloud, avec une automatisation complète, du provisionnement à l’exécution de la stratégie. Les mêmes étapes peuvent être adaptées à d’autres robots de trading ou à d’autres projets basés sur le cloud.
Avant de partir :
- N’oubliez pas de nettoyer régulièrement les journaux et les AMI inutilisés afin d’éviter des coûts AWS inutiles.
- Pour une utilisation plus avancée, telle que le backtesting sur des instances à forte puissance de calcul (ou futures instances GPU), consultez mon article complémentaire :
Lancement de Gekkoga sur une machine EC2 Spot haut de gamme - Pour des cours sur d’autres sujets liés à l’automatisation et à l’infrastructure, consultez :
Ressources externes qui pourraient vous être utiles :
- Documentation AWS : Données utilisateur et Cloud Init
- Guide des instances Spot AWS EC2
- GitHub officiel de Gekko
- Optimisation Gekkoga (référentiel communautaire)
- Meilleures pratiques en matière de gestion sécurisée des clés SSH (blog AWS)
Si cela vous a aidé, partagez votre expérience ou vos améliorations dans les commentaires !
Avez-vous rencontré des difficultés ou avez-vous des conseils pour automatiser Gekko à grande échelle ? Discutons-en ci-dessous.
En savoir plus sur SINECU.RE
Subscribe to get the latest posts sent to your email.